
The Future of AI Research: 20 Thesis Ideas for Undergraduate Students in Machine Learning and Deep Learning for 2023!
A comprehensive guide for crafting an original and innovative thesis in the field of ai..
By Aarafat Islam on 2023-01-11
“The beauty of machine learning is that it can be applied to any problem you want to solve, as long as you can provide the computer with enough examples.” — Andrew Ng
This article provides a list of 20 potential thesis ideas for an undergraduate program in machine learning and deep learning in 2023. Each thesis idea includes an introduction , which presents a brief overview of the topic and the research objectives . The ideas provided are related to different areas of machine learning and deep learning, such as computer vision, natural language processing, robotics, finance, drug discovery, and more. The article also includes explanations, examples, and conclusions for each thesis idea, which can help guide the research and provide a clear understanding of the potential contributions and outcomes of the proposed research. The article also emphasized the importance of originality and the need for proper citation in order to avoid plagiarism.
1. Investigating the use of Generative Adversarial Networks (GANs) in medical imaging: A deep learning approach to improve the accuracy of medical diagnoses.
Introduction: Medical imaging is an important tool in the diagnosis and treatment of various medical conditions. However, accurately interpreting medical images can be challenging, especially for less experienced doctors. This thesis aims to explore the use of GANs in medical imaging, in order to improve the accuracy of medical diagnoses.
2. Exploring the use of deep learning in natural language generation (NLG): An analysis of the current state-of-the-art and future potential.
Introduction: Natural language generation is an important field in natural language processing (NLP) that deals with creating human-like text automatically. Deep learning has shown promising results in NLP tasks such as machine translation, sentiment analysis, and question-answering. This thesis aims to explore the use of deep learning in NLG and analyze the current state-of-the-art models, as well as potential future developments.
3. Development and evaluation of deep reinforcement learning (RL) for robotic navigation and control.
Introduction: Robotic navigation and control are challenging tasks, which require a high degree of intelligence and adaptability. Deep RL has shown promising results in various robotics tasks, such as robotic arm control, autonomous navigation, and manipulation. This thesis aims to develop and evaluate a deep RL-based approach for robotic navigation and control and evaluate its performance in various environments and tasks.
4. Investigating the use of deep learning for drug discovery and development.
Introduction: Drug discovery and development is a time-consuming and expensive process, which often involves high failure rates. Deep learning has been used to improve various tasks in bioinformatics and biotechnology, such as protein structure prediction and gene expression analysis. This thesis aims to investigate the use of deep learning for drug discovery and development and examine its potential to improve the efficiency and accuracy of the drug development process.
5. Comparison of deep learning and traditional machine learning methods for anomaly detection in time series data.
Introduction: Anomaly detection in time series data is a challenging task, which is important in various fields such as finance, healthcare, and manufacturing. Deep learning methods have been used to improve anomaly detection in time series data, while traditional machine learning methods have been widely used as well. This thesis aims to compare deep learning and traditional machine learning methods for anomaly detection in time series data and examine their respective strengths and weaknesses.
Photo by Joanna Kosinska on Unsplash
6. Use of deep transfer learning in speech recognition and synthesis.
Introduction: Speech recognition and synthesis are areas of natural language processing that focus on converting spoken language to text and vice versa. Transfer learning has been widely used in deep learning-based speech recognition and synthesis systems to improve their performance by reusing the features learned from other tasks. This thesis aims to investigate the use of transfer learning in speech recognition and synthesis and how it improves the performance of the system in comparison to traditional methods.
7. The use of deep learning for financial prediction.
Introduction: Financial prediction is a challenging task that requires a high degree of intelligence and adaptability, especially in the field of stock market prediction. Deep learning has shown promising results in various financial prediction tasks, such as stock price prediction and credit risk analysis. This thesis aims to investigate the use of deep learning for financial prediction and examine its potential to improve the accuracy of financial forecasting.
8. Investigating the use of deep learning for computer vision in agriculture.
Introduction: Computer vision has the potential to revolutionize the field of agriculture by improving crop monitoring, precision farming, and yield prediction. Deep learning has been used to improve various computer vision tasks, such as object detection, semantic segmentation, and image classification. This thesis aims to investigate the use of deep learning for computer vision in agriculture and examine its potential to improve the efficiency and accuracy of crop monitoring and precision farming.
9. Development and evaluation of deep learning models for generative design in engineering and architecture.
Introduction: Generative design is a powerful tool in engineering and architecture that can help optimize designs and reduce human error. Deep learning has been used to improve various generative design tasks, such as design optimization and form generation. This thesis aims to develop and evaluate deep learning models for generative design in engineering and architecture and examine their potential to improve the efficiency and accuracy of the design process.
10. Investigating the use of deep learning for natural language understanding.
Introduction: Natural language understanding is a complex task of natural language processing that involves extracting meaning from text. Deep learning has been used to improve various NLP tasks, such as machine translation, sentiment analysis, and question-answering. This thesis aims to investigate the use of deep learning for natural language understanding and examine its potential to improve the efficiency and accuracy of natural language understanding systems.
Photo by UX Indonesia on Unsplash
11. Comparing deep learning and traditional machine learning methods for image compression.
Introduction: Image compression is an important task in image processing and computer vision. It enables faster data transmission and storage of image files. Deep learning methods have been used to improve image compression, while traditional machine learning methods have been widely used as well. This thesis aims to compare deep learning and traditional machine learning methods for image compression and examine their respective strengths and weaknesses.
12. Using deep learning for sentiment analysis in social media.
Introduction: Sentiment analysis in social media is an important task that can help businesses and organizations understand their customers’ opinions and feedback. Deep learning has been used to improve sentiment analysis in social media, by training models on large datasets of social media text. This thesis aims to use deep learning for sentiment analysis in social media, and evaluate its performance against traditional machine learning methods.
13. Investigating the use of deep learning for image generation.
Introduction: Image generation is a task in computer vision that involves creating new images from scratch or modifying existing images. Deep learning has been used to improve various image generation tasks, such as super-resolution, style transfer, and face generation. This thesis aims to investigate the use of deep learning for image generation and examine its potential to improve the quality and diversity of generated images.
14. Development and evaluation of deep learning models for anomaly detection in cybersecurity.
Introduction: Anomaly detection in cybersecurity is an important task that can help detect and prevent cyber-attacks. Deep learning has been used to improve various anomaly detection tasks, such as intrusion detection and malware detection. This thesis aims to develop and evaluate deep learning models for anomaly detection in cybersecurity and examine their potential to improve the efficiency and accuracy of cybersecurity systems.
15. Investigating the use of deep learning for natural language summarization.
Introduction: Natural language summarization is an important task in natural language processing that involves creating a condensed version of a text that preserves its main meaning. Deep learning has been used to improve various natural language summarization tasks, such as document summarization and headline generation. This thesis aims to investigate the use of deep learning for natural language summarization and examine its potential to improve the efficiency and accuracy of natural language summarization systems.
Photo by Windows on Unsplash
16. Development and evaluation of deep learning models for facial expression recognition.
Introduction: Facial expression recognition is an important task in computer vision and has many practical applications, such as human-computer interaction, emotion recognition, and psychological studies. Deep learning has been used to improve facial expression recognition, by training models on large datasets of images. This thesis aims to develop and evaluate deep learning models for facial expression recognition and examine their performance against traditional machine learning methods.
17. Investigating the use of deep learning for generative models in music and audio.
Introduction: Music and audio synthesis is an important task in audio processing, which has many practical applications, such as music generation and speech synthesis. Deep learning has been used to improve generative models for music and audio, by training models on large datasets of audio data. This thesis aims to investigate the use of deep learning for generative models in music and audio and examine its potential to improve the quality and diversity of generated audio.
18. Study the comparison of deep learning models with traditional algorithms for anomaly detection in network traffic.
Introduction: Anomaly detection in network traffic is an important task that can help detect and prevent cyber-attacks. Deep learning models have been used for this task, and traditional methods such as clustering and rule-based systems are widely used as well. This thesis aims to compare deep learning models with traditional algorithms for anomaly detection in network traffic and analyze the trade-offs between the models in terms of accuracy and scalability.
19. Investigating the use of deep learning for improving recommender systems.
Introduction: Recommender systems are widely used in many applications such as online shopping, music streaming, and movie streaming. Deep learning has been used to improve the performance of recommender systems, by training models on large datasets of user-item interactions. This thesis aims to investigate the use of deep learning for improving recommender systems and compare its performance with traditional content-based and collaborative filtering approaches.
20. Development and evaluation of deep learning models for multi-modal data analysis.
Introduction: Multi-modal data analysis is the task of analyzing and understanding data from multiple sources such as text, images, and audio. Deep learning has been used to improve multi-modal data analysis, by training models on large datasets of multi-modal data. This thesis aims to develop and evaluate deep learning models for multi-modal data analysis and analyze their potential to improve performance in comparison to single-modal models.
I hope that this article has provided you with a useful guide for your thesis research in machine learning and deep learning. Remember to conduct a thorough literature review and to include proper citations in your work, as well as to be original in your research to avoid plagiarism. I wish you all the best of luck with your thesis and your research endeavors!
Continue Learning
Art generating ai, the adoption of ai and machine learning in healthcare: what is the right way to proceed.
Let's find out how AI-powered technologies are being adopted in healthcare, given all the restrictions and benefits AI brings to the field.
How to Use Llama 2 with an API on AWS to Power Your AI Apps
Midjourney lighting guide: tips and advice, top 5 open-source image super-resolution projects to boost your image processing tasks, 6 best ai apis to build intelligent apps in 2023.
Research Topics & Ideas
Artifical Intelligence (AI) and Machine Learning (ML)

If you’re just starting out exploring AI-related research topics for your dissertation, thesis or research project, you’ve come to the right place. In this post, we’ll help kickstart your research topic ideation process by providing a hearty list of research topics and ideas , including examples from past studies.
PS – This is just the start…
We know it’s exciting to run through a list of research topics, but please keep in mind that this list is just a starting point . To develop a suitable research topic, you’ll need to identify a clear and convincing research gap , and a viable plan to fill that gap.
If this sounds foreign to you, check out our free research topic webinar that explores how to find and refine a high-quality research topic, from scratch. Alternatively, if you’d like hands-on help, consider our 1-on-1 coaching service .

AI-Related Research Topics & Ideas
Below you’ll find a list of AI and machine learning-related research topics ideas. These are intentionally broad and generic , so keep in mind that you will need to refine them a little. Nevertheless, they should inspire some ideas for your project.
- Developing AI algorithms for early detection of chronic diseases using patient data.
- The use of deep learning in enhancing the accuracy of weather prediction models.
- Machine learning techniques for real-time language translation in social media platforms.
- AI-driven approaches to improve cybersecurity in financial transactions.
- The role of AI in optimizing supply chain logistics for e-commerce.
- Investigating the impact of machine learning in personalized education systems.
- The use of AI in predictive maintenance for industrial machinery.
- Developing ethical frameworks for AI decision-making in healthcare.
- The application of ML algorithms in autonomous vehicle navigation systems.
- AI in agricultural technology: Optimizing crop yield predictions.
- Machine learning techniques for enhancing image recognition in security systems.
- AI-powered chatbots: Improving customer service efficiency in retail.
- The impact of AI on enhancing energy efficiency in smart buildings.
- Deep learning in drug discovery and pharmaceutical research.
- The use of AI in detecting and combating online misinformation.
- Machine learning models for real-time traffic prediction and management.
- AI applications in facial recognition: Privacy and ethical considerations.
- The effectiveness of ML in financial market prediction and analysis.
- Developing AI tools for real-time monitoring of environmental pollution.
- Machine learning for automated content moderation on social platforms.
- The role of AI in enhancing the accuracy of medical diagnostics.
- AI in space exploration: Automated data analysis and interpretation.
- Machine learning techniques in identifying genetic markers for diseases.
- AI-driven personal finance management tools.
- The use of AI in developing adaptive learning technologies for disabled students.

AI & ML Research Topic Ideas (Continued)
- Machine learning in cybersecurity threat detection and response.
- AI applications in virtual reality and augmented reality experiences.
- Developing ethical AI systems for recruitment and hiring processes.
- Machine learning for sentiment analysis in customer feedback.
- AI in sports analytics for performance enhancement and injury prevention.
- The role of AI in improving urban planning and smart city initiatives.
- Machine learning models for predicting consumer behaviour trends.
- AI and ML in artistic creation: Music, visual arts, and literature.
- The use of AI in automated drone navigation for delivery services.
- Developing AI algorithms for effective waste management and recycling.
- Machine learning in seismology for earthquake prediction.
- AI-powered tools for enhancing online privacy and data protection.
- The application of ML in enhancing speech recognition technologies.
- Investigating the role of AI in mental health assessment and therapy.
- Machine learning for optimization of renewable energy systems.
- AI in fashion: Predicting trends and personalizing customer experiences.
- The impact of AI on legal research and case analysis.
- Developing AI systems for real-time language interpretation for the deaf and hard of hearing.
- Machine learning in genomic data analysis for personalized medicine.
- AI-driven algorithms for credit scoring in microfinance.
- The use of AI in enhancing public safety and emergency response systems.
- Machine learning for improving water quality monitoring and management.
- AI applications in wildlife conservation and habitat monitoring.
- The role of AI in streamlining manufacturing processes.
- Investigating the use of AI in enhancing the accessibility of digital content for visually impaired users.
Recent AI & ML-Related Studies
While the ideas we’ve presented above are a decent starting point for finding a research topic in AI, they are fairly generic and non-specific. So, it helps to look at actual studies in the AI and machine learning space to see how this all comes together in practice.
Below, we’ve included a selection of AI-related studies to help refine your thinking. These are actual studies, so they can provide some useful insight as to what a research topic looks like in practice.
- An overview of artificial intelligence in diabetic retinopathy and other ocular diseases (Sheng et al., 2022)
- HOW DOES ARTIFICIAL INTELLIGENCE HELP ASTRONOMY? A REVIEW (Patel, 2022)
- Editorial: Artificial Intelligence in Bioinformatics and Drug Repurposing: Methods and Applications (Zheng et al., 2022)
- Review of Artificial Intelligence and Machine Learning Technologies: Classification, Restrictions, Opportunities, and Challenges (Mukhamediev et al., 2022)
- Will digitization, big data, and artificial intelligence – and deep learning–based algorithm govern the practice of medicine? (Goh, 2022)
- Flower Classifier Web App Using Ml & Flask Web Framework (Singh et al., 2022)
- Object-based Classification of Natural Scenes Using Machine Learning Methods (Jasim & Younis, 2023)
- Automated Training Data Construction using Measurements for High-Level Learning-Based FPGA Power Modeling (Richa et al., 2022)
- Artificial Intelligence (AI) and Internet of Medical Things (IoMT) Assisted Biomedical Systems for Intelligent Healthcare (Manickam et al., 2022)
- Critical Review of Air Quality Prediction using Machine Learning Techniques (Sharma et al., 2022)
- Artificial Intelligence: New Frontiers in Real–Time Inverse Scattering and Electromagnetic Imaging (Salucci et al., 2022)
- Machine learning alternative to systems biology should not solely depend on data (Yeo & Selvarajoo, 2022)
- Measurement-While-Drilling Based Estimation of Dynamic Penetrometer Values Using Decision Trees and Random Forests (García et al., 2022).
- Artificial Intelligence in the Diagnosis of Oral Diseases: Applications and Pitfalls (Patil et al., 2022).
- Automated Machine Learning on High Dimensional Big Data for Prediction Tasks (Jayanthi & Devi, 2022)
- Breakdown of Machine Learning Algorithms (Meena & Sehrawat, 2022)
- Technology-Enabled, Evidence-Driven, and Patient-Centered: The Way Forward for Regulating Software as a Medical Device (Carolan et al., 2021)
- Machine Learning in Tourism (Rugge, 2022)
- Towards a training data model for artificial intelligence in earth observation (Yue et al., 2022)
- Classification of Music Generality using ANN, CNN and RNN-LSTM (Tripathy & Patel, 2022)
As you can see, these research topics are a lot more focused than the generic topic ideas we presented earlier. So, in order for you to develop a high-quality research topic, you’ll need to get specific and laser-focused on a specific context with specific variables of interest. In the video below, we explore some other important things you’ll need to consider when crafting your research topic.
Get 1-On-1 Help
If you’re still unsure about how to find a quality research topic, check out our Research Topic Kickstarter service, which is the perfect starting point for developing a unique, well-justified research topic.

You Might Also Like:

can one come up with their own tppic and get a search
can one come up with their own title and get a search
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
Available Master's thesis topics in machine learning
Main content.
Here we list topics that are available. You may also be interested in our list of completed Master's theses .
Learning and inference with large Bayesian networks
Most learning and inference tasks with Bayesian networks are NP-hard. Therefore, one often resorts to using different heuristics that do not give any quality guarantees.
Task: Evaluate quality of large-scale learning or inference algorithms empirically.
Advisor: Pekka Parviainen
Sum-product networks
Traditionally, probabilistic graphical models use a graph structure to represent dependencies and independencies between random variables. Sum-product networks are a relatively new type of a graphical model where the graphical structure models computations and not the relationships between variables. The benefit of this representation is that inference (computing conditional probabilities) can be done in linear time with respect to the size of the network.
Potential thesis topics in this area: a) Compare inference speed with sum-product networks and Bayesian networks. Characterize situations when one model is better than the other. b) Learning the sum-product networks is done using heuristic algorithms. What is the effect of approximation in practice?
Bayesian Bayesian networks
The naming of Bayesian networks is somewhat misleading because there is nothing Bayesian in them per se; A Bayesian network is just a representation of a joint probability distribution. One can, of course, use a Bayesian network while doing Bayesian inference. One can also learn Bayesian networks in a Bayesian way. That is, instead of finding an optimal network one computes the posterior distribution over networks.
Task: Develop algorithms for Bayesian learning of Bayesian networks (e.g., MCMC, variational inference, EM)
Large-scale (probabilistic) matrix factorization
The idea behind matrix factorization is to represent a large data matrix as a product of two or more smaller matrices.They are often used in, for example, dimensionality reduction and recommendation systems. Probabilistic matrix factorization methods can be used to quantify uncertainty in recommendations. However, large-scale (probabilistic) matrix factorization is computationally challenging.
Potential thesis topics in this area: a) Develop scalable methods for large-scale matrix factorization (non-probabilistic or probabilistic), b) Develop probabilistic methods for implicit feedback (e.g., recommmendation engine when there are no rankings but only knowledge whether a customer has bought an item)
Bayesian deep learning
Standard deep neural networks do not quantify uncertainty in predictions. On the other hand, Bayesian methods provide a principled way to handle uncertainty. Combining these approaches leads to Bayesian neural networks. The challenge is that Bayesian neural networks can be cumbersome to use and difficult to learn.
The task is to analyze Bayesian neural networks and different inference algorithms in some simple setting.
Deep learning for combinatorial problems
Deep learning is usually applied in regression or classification problems. However, there has been some recent work on using deep learning to develop heuristics for combinatorial optimization problems; see, e.g., [1] and [2].
Task: Choose a combinatorial problem (or several related problems) and develop deep learning methods to solve them.
References: [1] Vinyals, Fortunato and Jaitly: Pointer networks. NIPS 2015. [2] Dai, Khalil, Zhang, Dilkina and Song: Learning Combinatorial Optimization Algorithms over Graphs. NIPS 2017.
Advisors: Pekka Parviainen, Ahmad Hemmati
Estimating the number of modes of an unknown function
Mode seeking considers estimating the number of local maxima of a function f. Sometimes one can find modes by, e.g., looking for points where the derivative of the function is zero. However, often the function is unknown and we have only access to some (possibly noisy) values of the function.
In topological data analysis, we can analyze topological structures using persistent homologies. For 1-dimensional signals, this can translate into looking at the birth/death persistence diagram, i.e. the birth and death of connected topological components as we expand the space around each point where we have observed our function. These observations turn out to be closely related to the modes (local maxima) of the function. A recent paper [1] proposed an efficient method for mode seeking.
In this project, the task is to extend the ideas from [1] to get a probabilistic estimate on the number of modes. To this end, one has to use probabilistic methods such as Gaussian processes.
[1] U. Bauer, A. Munk, H. Sieling, and M. Wardetzky. Persistence barcodes versus Kolmogorov signatures: Detecting modes of one-dimensional signals. Foundations of computational mathematics17:1 - 33, 2017.
Advisors: Pekka Parviainen , Nello Blaser
Causal Abstraction Learning
We naturally make sense of the world around us by working out causal relationships between objects and by representing in our minds these objects with different degrees of approximation and detail. Both processes are essential to our understanding of reality, and likely to be fundamental for developing artificial intelligence. The first process may be expressed using the formalism of structural causal models, while the second can be grounded in the theory of causal abstraction [1]. This project will consider the problem of learning an abstraction between two given structural causal models. The primary goal will be the development of efficient algorithms able to learn a meaningful abstraction between the given causal models. [1] Rubenstein, Paul K., et al. "Causal consistency of structural equation models." arXiv preprint arXiv:1707.00819 (2017).
Advisor: Fabio Massimo Zennaro
Causal Bandits
"Multi-armed bandit" is an informal name for slot machines, and the formal name of a large class of problems where an agent has to choose an action among a range of possibilities without knowing the ensuing rewards. Multi-armed bandit problems are one of the most essential reinforcement learning problems where an agent is directly faced with an exploitation-exploration trade-off. This project will consider a class of multi-armed bandits where an agent, upon taking an action, interacts with a causal system [1]. The primary goal will be the development of learning strategies that takes advantage of the underlying causal system in order to learn optimal policies in a shortest amount of time. [1] Lattimore, Finnian, Tor Lattimore, and Mark D. Reid. "Causal bandits: Learning good interventions via causal inference." Advances in neural information processing systems 29 (2016).
Causal Modelling for Battery Manufacturing
Lithium-ion batteries are poised to be one of the most important sources of energy in the near future. Yet, the process of manufacturing these batteries is very hard to model and control. Optimizing the different phases of production to maximize the lifetime of the batteries is a non-trivial challenge since physical models are limited in scope and collecting experimental data is extremely expensive and time-consuming [1]. This project will consider the problem of aggregating and analyzing data regarding a few stages in the process of battery manufacturing. The primary goal will be the development of algorithms for transporting and integrating data collected in different contexts, as well as the use of explainable algorithms to interpret them. [1] Niri, Mona Faraji, et al. "Quantifying key factors for optimised manufacturing of Li-ion battery anode and cathode via artificial intelligence." Energy and AI 7 (2022): 100129.
Advisor: Fabio Massimo Zennaro , Mona Faraji Niri
Reinforcement Learning for Computer Security
The field of computer security presents a wide variety of challenging problems for artificial intelligence and autonomous agents. Guaranteeing the security of a system against attacks and penetrations by malicious hackers has always been a central concern of this field, and machine learning could now offer a substantial contribution. Security capture-the-flag simulations are particularly well-suited as a testbed for the application and development of reinforcement learning algorithms [1]. This project will consider the use of reinforcement learning for the preventive purpose of testing systems and discovering vulnerabilities before they can be exploited. The primary goal will be the modelling of capture-the-flag challenges of interest and the development of reinforcement learning algorithms that can solve them. [1] Erdodi, Laszlo, and Fabio Massimo Zennaro. "The Agent Web Model--Modelling web hacking for reinforcement learning." arXiv preprint arXiv:2009.11274 (2020).
Advisor: Fabio Massimo Zennaro , Laszlo Tibor Erdodi
Approaches to AI Safety
The world and the Internet are more and more populated by artificial autonomous agents carrying out tasks on our behalf. Many of these agents are provided with an objective and they learn their behaviour trying to achieve their objective as better as they can. However, this approach can not guarantee that an agent, while learning its behaviour, will not undertake actions that may have unforeseen and undesirable effects. Research in AI safety tries to design autonomous agent that will behave in a predictable and safe way [1]. This project will consider specific problems and novel solution in the domain of AI safety and reinforcement learning. The primary goal will be the development of innovative algorithms and their implementation withing established frameworks. [1] Amodei, Dario, et al. "Concrete problems in AI safety." arXiv preprint arXiv:1606.06565 (2016).
Reinforcement Learning for Super-modelling
Super-modelling [1] is a technique designed for combining together complex dynamical models: pre-trained models are aggregated with messages and information being exchanged in order synchronize the behavior of the different modles and produce more accurate and reliable predictions. Super-models are used, for instance, in weather or climate science, where pre-existing models are ensembled together and their states dynamically aggregated to generate more realistic simulations.
This project will consider how reinforcement learning algorithms may be used to solve the coordination problem among the individual models forming a super-model. The primary goal will be the formulation of the super-modelling problem within the reinforcement learning framework and the study of custom RL algorithms to improve the overall performance of super-models.
[1] Schevenhoven, Francine, et al. "Supermodeling: improving predictions with an ensemble of interacting models." Bulletin of the American Meteorological Society 104.9 (2023): E1670-E1686.
Advisor: Fabio Massimo Zennaro , Francine Janneke Schevenhoven
The Topology of Flight Paths
Air traffic data tells us the position, direction, and speed of an aircraft at a given time. In other words, if we restrict our focus to a single aircraft, we are looking at a multivariate time-series. We can visualize the flight path as a curve above earth's surface quite geometrically. Topological data analysis (TDA) provides different methods for analysing the shape of data. Consequently, TDA may help us to extract meaningful features from the air traffic data. Although the typical flight path shapes may not be particularly intriguing, we can attempt to identify more intriguing patterns or “abnormal” manoeuvres, such as aborted landings, go-arounds, or diverts.
Advisor: Odin Hoff Gardå , Nello Blaser
Automatic hyperparameter selection for isomap
Isomap is a non-linear dimensionality reduction method with two free hyperparameters (number of nearest neighbors and neighborhood radius). Different hyperparameters result in dramatically different embeddings. Previous methods for selecting hyperparameters focused on choosing one optimal hyperparameter. In this project, you will explore the use of persistent homology to find parameter ranges that result in stable embeddings. The project has theoretic and computational aspects.
Advisor: Nello Blaser
Validate persistent homology
Persistent homology is a generalization of hierarchical clustering to find more structure than just the clusters. Traditionally, hierarchical clustering has been evaluated using resampling methods and assessing stability properties. In this project you will generalize these resampling methods to develop novel stability properties that can be used to assess persistent homology. This project has theoretic and computational aspects.
Topological Ancombs quartet
This topic is based on the classical Ancombs quartet and families of point sets with identical 1D persistence ( https://arxiv.org/abs/2202.00577 ). The goal is to generate more interesting datasets using the simulated annealing methods presented in ( http://library.usc.edu.ph/ACM/CHI%202017/1proc/p1290.pdf ). This project is mostly computational.
Persistent homology vectorization with cycle location
There are many methods of vectorizing persistence diagrams, such as persistence landscapes, persistence images, PersLay and statistical summaries. Recently we have designed algorithms to in some cases efficiently detect the location of persistence cycles. In this project, you will vectorize not just the persistence diagram, but additional information such as the location of these cycles. This project is mostly computational with some theoretic aspects.
Divisive covers
Divisive covers are a divisive technique for generating filtered simplicial complexes. They original used a naive way of dividing data into a cover. In this project, you will explore different methods of dividing space, based on principle component analysis, support vector machines and k-means clustering. In addition, you will explore methods of using divisive covers for classification. This project will be mostly computational.
Learning Acquisition Functions for Cost-aware Bayesian Optimization
This is a follow-up project of an earlier Master thesis that developed a novel method for learning Acquisition Functions in Bayesian Optimization through the use of Reinforcement Learning. The goal of this project is to further generalize this method (more general input, learned cost-functions) and apply it to hyperparameter optimization for neural networks.
Advisors: Nello Blaser , Audun Ljone Henriksen
Stable updates
This is a follow-up project of an earlier Master thesis that introduced and studied empirical stability in the context of tree-based models. The goal of this project is to develop stable update methods for deep learning models. You will design sevaral stable methods and empirically compare them (in terms of loss and stability) with a baseline and with one another.
Advisors: Morten Blørstad , Nello Blaser
Multimodality in Bayesian neural network ensembles
One method to assess uncertainty in neural network predictions is to use dropout or noise generators at prediction time and run every prediction many times. This leads to a distribution of predictions. Informatively summarizing such probability distributions is a non-trivial task and the commonly used means and standard deviations result in the loss of crucial information, especially in the case of multimodal distributions with distinct likely outcomes. In this project, you will analyze such multimodal distributions with mixture models and develop ways to exploit such multimodality to improve training. This project can have theoretical, computational and applied aspects.
Wet area segmentation for rivers
NORCE LFI is working on digitizing wetted areas in rivers. You will apply different machine learning techniques for distinguishing water bodies (rivers) from land based on drone aerial (RGB) pictures. This is important for water management and assessing effects of hydropower on river ecosystems (residual flow, stranding of fish and spawning areas). We have a database of approximately 100 rivers (aerial pictures created from totally ca. 120.000 single pictures with Structure from Motion, single pictures available as well) and several of these rivers are flown at 2-4 different discharges, taken in different seasons and with different weather patterns. For ca. 50 % of the pictures the wetted area is digitized for training (GIS shapefile), most (>90 % of single pictures) cover water surface and land. Possible challenges include shading, reflectance from the water surface, different water/ground colours and wet surfaces on land. This is an applied topic, where you will try many different machine learning techniques to find the best solution for the mapping tasks by NORCE LFI.
Advisor: Nello Blaser , Sebastian Franz Stranzl
Learning a hierarchical metric
Often, labels have defined relationships to each other, for instance in a hierarchical taxonomy. E.g. ImageNet labels are derived from the WordNet graph, and biological species are taxonomically related, and can have similarities depending on life stage, sex, or other properties.
ArcFace is an alternative loss function that aims for an embedding that is more generally useful than softmax. It is commonly used in metric learning/few shot learning cases.
Here, we will develop a metric learning method that learns from data with hierarchical labels. Using multiple ArcFace heads, we will simultaneously learn to place representations to optimize the leaf label as well as intermediate labels on the path from leaf to root of the label tree. Using taxonomically classified plankton image data, we will measure performance as a function of ArcFace parameters (sharpness/temperature and margins -- class-wise or level-wise), and compare the results to existing methods.
Advisor: Ketil Malde ( [email protected] )
Self-supervised object detection in video
One challenge with learning object detection is that in many scenes that stretch off into the distance, annotating small, far-off, or blurred objects is difficult. It is therefore desirable to learn from incompletely annotated scenes, and one-shot object detectors may suffer from incompletely annotated training data.
To address this, we will use a region-propsal algorithm (e.g. SelectiveSearch) to extract potential crops from each frame. Classification will be based on two approaches: a) training based on annotated fish vs random similarly-sized crops without annotations, and b) using a self-supervised method to build a representation for crops, and building a classifier for the extracted regions. The method will be evaluated against one-shot detectors and other training regimes.
If successful, the method will be applied to fish detection and tracking in videos from baited and unbaited underwater traps, and used to estimate abundance of various fish species.
See also: Benettino (2016): https://link.springer.com/chapter/10.1007/978-3-319-48881-3_56
Representation learning for object detection
While traditional classifiers work well with data that is labeled with disjoint classes and reasonably balanced class abundances, reality is often less clean. An alternative is to learn a vectors space embedding that reflects semantic relationships between objects, and deriving classes from this representation. This is especially useful for few-shot classification (ie. very few examples in the training data).
The task here is to extend a modern object detector (e.g. Yolo v8) to output an embedding of the identified object. Instead of a softmax classifier, we can learn the embedding either in a supervised manner (using annotations on frames) by attaching an ArcFace or other supervised metric learning head. Alternatively, the representation can be learned from tracked detections over time using e.g. a contrastive loss function to keep the representation for an object (approximately) constant over time. The performance of the resulting object detector will be measured on underwater videos, targeting species detection and/or indiviual recognition (re-ID).
Time-domain object detection
Object detectors for video are normally trained on still frames, but it is evident (from human experience) that using time domain information is more effective. I.e., it can be hard to identify far-off or occluded objects in still images, but movement in time often reveals them.
Here we will extend a state of the art object detector (e.g. yolo v8) with time domain data. Instead of using a single frame as input, the model will be modified to take a set of frames surrounding the annotated frame as input. Performance will be compared to using single-frame detection.
Large-scale visualization of acoustic data
The Institute of Marine Research has decades of acoustic data collected in various surveys. These data are in the process of being converted to data formats that can be processed and analyzed more easily using packages like Xarray and Dask.
The objective is to make these data more accessible to regular users by providing a visual front end. The user should be able to quickly zoom in and out, perform selection, export subsets, apply various filters and classifiers, and overlay annotations and other relevant auxiliary data.
Learning acoustic target classification from simulation
Broadband echosounders emit a complex signal that spans a large frequency band. Different targets will reflect, absorb, and generate resonance at different amplitudes and frequencies, and it is therefore possible to classify targets at much higher resolution and accuracy than before. Due to the complexity of the received signals, deriving effective profiles that can be used to identify targets is difficult.
Here we will use simulated frequency spectra from geometric objects with various shapes, orientation, and other properties. We will train ML models to estimate (recover) the geometric and material properties of objects based on these spectra. The resulting model will be applied to read broadband data, and compared to traditional classification methods.
Online learning in real-time systems
Build a model for the drilling process by using the Virtual simulator OpenLab ( https://openlab.app/ ) for real-time data generation and online learning techniques. The student will also do a short survey of existing online learning techniques and learn how to cope with errors and delays in the data.
Advisor: Rodica Mihai
Building a finite state automaton for the drilling process by using queries and counterexamples
Datasets will be generated by using the Virtual simulator OpenLab ( https://openlab.app/ ). The student will study the datasets and decide upon a good setting to extract a finite state automaton for the drilling process. The student will also do a short survey of existing techniques for extracting finite state automata from process data. We present a novel algorithm that uses exact learning and abstraction to extract a deterministic finite automaton describing the state dynamics of a given trained RNN. We do this using Angluin's L*algorithm as a learner and the trained RNN as an oracle. Our technique efficiently extracts accurate automata from trained RNNs, even when the state vectors are large and require fine differentiation.arxiv.org
Scaling Laws for Language Models in Generative AI
Large Language Models (LLM) power today's most prominent language technologies in Generative AI like ChatGPT, which, in turn, are changing the way that people access information and solve tasks of many kinds.
A recent interest on scaling laws for LLMs has shown trends on understanding how well they perform in terms of factors like the how much training data is used, how powerful the models are, or how much computational cost is allocated. (See, for example, Kaplan et al. - "Scaling Laws for Neural Language Models”, 2020.)
In this project, the task will consider to study scaling laws for different language models and with respect with one or multiple modeling factors.
Advisor: Dario Garigliotti
Applications of causal inference methods to omics data
Many hard problems in machine learning are directly linked to causality [1]. The graphical causal inference framework developed by Judea Pearl can be traced back to pioneering work by Sewall Wright on path analysis in genetics and has inspired research in artificial intelligence (AI) [1].
The Michoel group has developed the open-source tool Findr [2] which provides efficient implementations of mediation and instrumental variable methods for applications to large sets of omics data (genomics, transcriptomics, etc.). Findr works well on a recent data set for yeast [3].
We encourage students to explore promising connections between the fiels of causal inference and machine learning. Feel free to contact us to discuss projects related to causal inference. Possible topics include: a) improving methods based on structural causal models, b) evaluating causal inference methods on data for model organisms, c) comparing methods based on causal models and neural network approaches.
References:
1. Schölkopf B, Causality for Machine Learning, arXiv (2019): https://arxiv.org/abs/1911.10500
2. Wang L and Michoel T. Efficient and accurate causal inference with hidden confounders from genome-transcriptome variation data. PLoS Computational Biology 13:e1005703 (2017). https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1005703
3. Ludl A and and Michoel T. Comparison between instrumental variable and mediation-based methods for reconstructing causal gene networks in yeast. arXiv:2010.07417 https://arxiv.org/abs/2010.07417
Advisors: Adriaan Ludl , Tom Michoel
Space-Time Linkage of Fish Distribution to Environmental Conditions
Conditions in the marine environment, such as, temperature and currents, influence the spatial distribution and migration patterns of marine species. Hence, understanding the link between environmental factors and fish behavior is crucial in predicting, e.g., how fish populations may respond to climate change. Deriving this link is challenging because it requires analysis of two types of datasets (i) large environmental (currents, temperature) datasets that vary in space and time, and (ii) sparse and sporadic spatial observations of fish populations.
Project goal
The primary goal of the project is to develop a methodology that helps predict how spatial distribution of two fish stocks (capelin and mackerel) change in response to variability in the physical marine environment (ocean currents and temperature). The information can also be used to optimize data collection by minimizing time spent in spatial sampling of the populations.
The project will focus on the use of machine learning and/or causal inference algorithms. As a first step, we use synthetic (fish and environmental) data from analytic models that couple the two data sources. Because the ‘truth’ is known, we can judge the efficiency and error margins of the methodologies. We then apply the methodologies to real world (empirical) observations.
Advisors: Tom Michoel , Sam Subbey .
Towards precision medicine for cancer patient stratification
On average, a drug or a treatment is effective in only about half of patients who take it. This means patients need to try several until they find one that is effective at the cost of side effects associated with every treatment. The ultimate goal of precision medicine is to provide a treatment best suited for every individual. Sequencing technologies have now made genomics data available in abundance to be used towards this goal.
In this project we will specifically focus on cancer. Most cancer patients get a particular treatment based on the cancer type and the stage, though different individuals will react differently to a treatment. It is now well established that genetic mutations cause cancer growth and spreading and importantly, these mutations are different in individual patients. The aim of this project is use genomic data allow to better stratification of cancer patients, to predict the treatment most likely to work. Specifically, the project will use machine learning approach to integrate genomic data and build a classifier for stratification of cancer patients.
Advisor: Anagha Joshi
Unraveling gene regulation from single cell data
Multi-cellularity is achieved by precise control of gene expression during development and differentiation and aberrations of this process leads to disease. A key regulatory process in gene regulation is at the transcriptional level where epigenetic and transcriptional regulators control the spatial and temporal expression of the target genes in response to environmental, developmental, and physiological cues obtained from a signalling cascade. The rapid advances in sequencing technology has now made it feasible to study this process by understanding the genomewide patterns of diverse epigenetic and transcription factors as well as at a single cell level.
Single cell RNA sequencing is highly important, particularly in cancer as it allows exploration of heterogenous tumor sample, obstructing therapeutic targeting which leads to poor survival. Despite huge clinical relevance and potential, analysis of single cell RNA-seq data is challenging. In this project, we will develop strategies to infer gene regulatory networks using network inference approaches (both supervised and un-supervised). It will be primarily tested on the single cell datasets in the context of cancer.
Developing a Stress Granule Classifier
To carry out the multitude of functions 'expected' from a human cell, the cell employs a strategy of division of labour, whereby sub-cellular organelles carry out distinct functions. Thus we traditionally understand organelles as distinct units defined both functionally and physically with a distinct shape and size range. More recently a new class of organelles have been discovered that are assembled and dissolved on demand and are composed of liquid droplets or 'granules'. Granules show many properties characteristic of liquids, such as flow and wetting, but they can also assume many shapes and indeed also fluctuate in shape. One such liquid organelle is a stress granule (SG).
Stress granules are pro-survival organelles that assemble in response to cellular stress and important in cancer and neurodegenerative diseases like Alzheimer's. They are liquid or gel-like and can assume varying sizes and shapes depending on their cellular composition.
In a given experiment we are able to image the entire cell over a time series of 1000 frames; from which we extract a rough estimation of the size and shape of each granule. Our current method is susceptible to noise and a granule may be falsely rejected if the boundary is drawn poorly in a small majority of frames. Ideally, we would also like to identify potentially interesting features, such as voids, in the accepted granules.
We are interested in applying a machine learning approach to develop a descriptor for a 'classic' granule and furthermore classify them into different functional groups based on disease status of the cell. This method would be applied across thousands of granules imaged from control and disease cells. We are a multi-disciplinary group consisting of biologists, computational scientists and physicists.
Advisors: Sushma Grellscheid , Carl Jones
Machine Learning based Hyperheuristic algorithm
Develop a Machine Learning based Hyper-heuristic algorithm to solve a pickup and delivery problem. A hyper-heuristic is a heuristics that choose heuristics automatically. Hyper-heuristic seeks to automate the process of selecting, combining, generating or adapting several simpler heuristics to efficiently solve computational search problems [Handbook of Metaheuristics]. There might be multiple heuristics for solving a problem. Heuristics have their own strength and weakness. In this project, we want to use machine-learning techniques to learn the strength and weakness of each heuristic while we are using them in an iterative search for finding high quality solutions and then use them intelligently for the rest of the search. Once a new information is gathered during the search the hyper-heuristic algorithm automatically adjusts the heuristics.
Advisor: Ahmad Hemmati
Machine learning for solving satisfiability problems and applications in cryptanalysis
Advisor: Igor Semaev
Hybrid modeling approaches for well drilling with Sintef
Several topics are available.
"Flow models" are first-principles models simulating the flow, temperature and pressure in a well being drilled. Our project is exploring "hybrid approaches" where these models are combined with machine learning models that either learn from time series data from flow model runs or from real-world measurements during drilling. The goal is to better detect drilling problems such as hole cleaning, make more accurate predictions and correctly learn from and interpret real-word data.
The "surrogate model" refers to a ML model which learns to mimic the flow model by learning from the model inputs and outputs. Use cases for surrogate models include model predictions where speed is favoured over accuracy and exploration of parameter space.
Surrogate models with active Learning
While it is possible to produce a nearly unlimited amount of training data by running the flow model, the surrogate model may still perform poorly if it lacks training data in the part of the parameter space it operates in or if it "forgets" areas of the parameter space by being fed too much data from a narrow range of parameters.
The goal of this thesis is to build a surrogate model (with any architecture) for some restricted parameter range and implement an active learning approach where the ML requests more model runs from the flow model in the parts of the parameter space where it is needed the most. The end result should be a surrogate model that is quick and performs acceptably well over the whole defined parameter range.
Surrogate models trained via adversarial learning
How best to train surrogate models from runs of the flow model is an open question. This master thesis would use the adversarial learning approach to build a surrogate model which to its "adversary" becomes indistinguishable from the output of an actual flow model run.
GPU-based Surrogate models for parameter search
While CPU speed largely stalled 20 years ago in terms of working frequency on single cores, multi-core CPUs and especially GPUs took off and delivered increases in computational power by parallelizing computations.
Modern machine learning such as deep learning takes advantage this boom in computing power by running on GPUs.
The SINTEF flow models in contrast, are software programs that runs on a CPU and does not happen to utilize multi-core CPU functionality. The model runs advance time-step by time-step and each time step relies on the results from the previous time step. The flow models are therefore fundamentally sequential and not well suited to massive parallelization.
It is however of interest to run different model runs in parallel, to explore parameter spaces. The use cases for this includes model calibration, problem detection and hypothesis generation and testing.
The task of this thesis is to implement an ML-based surrogate model in such a way that many surrogate model outputs can be produced at the same time using a single GPU. This will likely entail some trade off with model size and maybe some coding tricks.
Uncertainty estimates of hybrid predictions (Lots of room for creativity, might need to steer it more, needs good background literature)
When using predictions from a ML model trained on time series data, it is useful to know if it's accurate or should be trusted. The student is challenged to develop hybrid approaches that incorporates estimates of uncertainty. Components could include reporting variance from ML ensembles trained on a diversity of time series data, implementation of conformal predictions, analysis of training data parameter ranges vs current input, etc. The output should be a "traffic light signal" roughly indicating the accuracy of the predictions.
Transfer learning approaches
We're assuming an ML model is to be used for time series prediction
It is possible to train an ML on a wide range of scenarios in the flow models, but we expect that to perform well, the model also needs to see model runs representative of the type of well and drilling operation it will be used in. In this thesis the student implements a transfer learning approach, where the model is trained on general model runs and fine-tuned on a most representative data set.
(Bonus1: implementing one-shot learning, Bonus2: Using real-world data in the fine-tuning stage)
ML capable of reframing situations
When a human oversees an operation like well drilling, she has a mental model of the situation and new data such as pressure readings from the well is interpreted in light of this model. This is referred to as "framing" and is the normal mode of work. However, when a problem occurs, it becomes harder to reconcile the data with the mental model. The human then goes into "reframing", building a new mental model that includes the ongoing problem. This can be seen as a process of hypothesis generation and testing.
A computer model however, lacks re-framing. A flow model will keep making predictions under the assumption of no problems and a separate alarm system will use the deviation between the model predictions and reality to raise an alarm. This is in a sense how all alarm systems work, but it means that the human must discard the computer model as a tool at the same time as she's handling a crisis.
The student is given access to a flow model and a surrogate model which can learn from model runs both with and without hole cleaning and is challenged to develop a hybrid approach where the ML+flow model continuously performs hypothesis generation and testing and is able to "switch" into predictions of a hole cleaning problem and different remediations of this.
Advisor: Philippe Nivlet at Sintef together with advisor from UiB
Explainable AI at Equinor
In the project Machine Teaching for XAI (see https://xai.w.uib.no ) a master thesis in collaboration between UiB and Equinor.
Advisor: One of Pekka Parviainen/Jan Arne Telle/Emmanuel Arrighi + Bjarte Johansen from Equinor.
Explainable AI at Eviny
In the project Machine Teaching for XAI (see https://xai.w.uib.no ) a master thesis in collaboration between UiB and Eviny.
Advisor: One of Pekka Parviainen/Jan Arne Telle/Emmanuel Arrighi + Kristian Flikka from Eviny.
If you want to suggest your own topic, please contact Pekka Parviainen , Fabio Massimo Zennaro or Nello Blaser .

- Latest News
- Cryptocurrencies
- White Papers
Top 10 Research and Thesis Topics for ML Projects in 2022

This article features the top 10 research and thesis topics for ML projects for students to try in 2022
In this tech-driven world, selecting research and thesis topics in machine learning projects is the first choice of masters and Doctorate scholars. Selecting and working on a thesis topic in machine learning is not an easy task as machine learning uses statistical algorithms to make computers work in a certain way without being explicitly programmed. Achieving mastery over machine learning (ML) is becoming increasingly crucial for all the students in this field. Both artificial intelligence and machine learning complement each other. So, if you are a beginner, the best thing you can do is work on some ML projects. This article features the top 10 research and thesis topics for ML projects for students to try in 2022.
Text Mining and Text Classification
Text mining (also referred to as text analytics) is an artificial intelligence (AI) technology that uses natural language processing (NLP) to transform the free (unstructured) text in documents and databases into normalized, structured data suitable for analysis or to drive machine learning (ML) algorithms. Text classification tools categorize text by understanding its overall meaning, without predefined categories being explicitly present within the text. This is one of the best research and thesis topics for ML projects.
Image-Based Applications
An image-based test consists of a sequence of operations on UI elements in your tested application: clicks (for desktop and web applications), touches (for mobile applications), drag and drop operations, checkpoints, and so on. In image applications, one must first get familiar with masks, convolution, edge, and corner detection to be able to extract useful information from images and further use them for applications like image segmentation, keypoints extraction, and more.
Machine Vision
Using machine learning -based/mathematical techniques to enable machines to do specific tasks. For example, watermarking, face identification from datasets of images with rotation and different camera angles, criminals identification from surveillance cameras (video and series of images), handwriting and personal signature classification, object detection/recognition.
Clustering or cluster analysis is a machine learning technique, which groups the unlabeled dataset. It can be defined as "A way of grouping the data points into different clusters, consisting of similar data points. For example Graph clustering, data clustering, density-based clustering, and more. Clustering is one of the best research and thesis topics for ML projects.
Optimization
A) Population-based optimization inspired from a natural mechanism: Black-box optimization, multi/many-objective optimization, evolutionary methods (Genetic Algorithm, Genetic Programming, Memetic Programming), Metaheuristics (e.g., PSO, ABC, SA)
B) Exact/Mathematical Models: Convex optimization, Bi-Convex, and Semi-Convex optimization, Gradient Descent, Block Coordinate Descent, Manifold Optimization, and Algebraic Models
Voice Classification
Voice classification or sound classification can be referred to as the process of analyzing audio recordings. Voice and Speech Recognition, Signal Processing, Message Embedding, Message Extraction from Voice Encoded, and more are the best research and thesis topics for ML projects.
Sentiment Analysis
Sentiment analysis is one of the best Machine Learning projects well-known to uncover emotions in the text. By analyzing movie reviews, customer feedback, support tickets, companies may discover many interesting things. So learning how to build sentiment analysis models is quite a practical skill. There is no need to collect the data yourself. To train and test your model, use the biggest open-source database for sentiment analysis created by IMDb.
Recommendation Framework Project
This a rich dataset assortment containing a different scope of datasets accumulated from famous sites like Goodreads book audits, Amazon item surveys, online media, and so forth You will probably fabricate a recommendation engine (like the ones utilized by Amazon and Netflix) that can create customized recommendations for items, films, music, and so on, because of client inclinations, needs, and online conduct.
Mall Customers' Project
As the name suggests, the mall customers' dataset includes the records of people who visited the mall, such as gender, age, customer ID, annual income, spending score, etc. You will build a model that will use this data to segment the customers into different groups based on their behavior patterns. Such customer segmentation is a highly useful marketing tactic used by brands and marketers to boost sales and revenue while also increasing customer satisfaction.
Object Detection with Deep Learning
Object Detection with Deep Learning is one of the interesting machine learning projects to create. When it comes to image classification, Deep Neural Networks (DNNs) should be your go-to choice. While DNNs are already used in many real-world image classification applications, it is one of the best ML projects that aims to crank it up a notch. In this Machine Learning project, you will solve the problem of object detection by leveraging DNNs.
Disclaimer: Analytics Insight does not provide financial advice or guidance. Also note that the cryptocurrencies mentioned/listed on the website could potentially be scams, i.e. designed to induce you to invest financial resources that may be lost forever and not be recoverable once investments are made. You are responsible for conducting your own research (DYOR) before making any investments. Read more here.
Related Stories
Machine Learning - CMU

PhD Dissertations
[all are .pdf files].
Learning Models that Match Jacob Tyo, 2024
Improving Human Integration across the Machine Learning Pipeline Charvi Rastogi, 2024
Reliable and Practical Machine Learning for Dynamic Healthcare Settings Helen Zhou, 2023
Automatic customization of large-scale spiking network models to neuronal population activity (unavailable) Shenghao Wu, 2023
Estimation of BVk functions from scattered data (unavailable) Addison J. Hu, 2023
Rethinking object categorization in computer vision (unavailable) Jayanth Koushik, 2023
Advances in Statistical Gene Networks Jinjin Tian, 2023 Post-hoc calibration without distributional assumptions Chirag Gupta, 2023
The Role of Noise, Proxies, and Dynamics in Algorithmic Fairness Nil-Jana Akpinar, 2023
Collaborative learning by leveraging siloed data Sebastian Caldas, 2023
Modeling Epidemiological Time Series Aaron Rumack, 2023
Human-Centered Machine Learning: A Statistical and Algorithmic Perspective Leqi Liu, 2023
Uncertainty Quantification under Distribution Shifts Aleksandr Podkopaev, 2023
Probabilistic Reinforcement Learning: Using Data to Define Desired Outcomes, and Inferring How to Get There Benjamin Eysenbach, 2023
Comparing Forecasters and Abstaining Classifiers Yo Joong Choe, 2023
Using Task Driven Methods to Uncover Representations of Human Vision and Semantics Aria Yuan Wang, 2023
Data-driven Decisions - An Anomaly Detection Perspective Shubhranshu Shekhar, 2023
Applied Mathematics of the Future Kin G. Olivares, 2023
METHODS AND APPLICATIONS OF EXPLAINABLE MACHINE LEARNING Joon Sik Kim, 2023
NEURAL REASONING FOR QUESTION ANSWERING Haitian Sun, 2023
Principled Machine Learning for Societally Consequential Decision Making Amanda Coston, 2023
Long term brain dynamics extend cognitive neuroscience to timescales relevant for health and physiology Maxwell B. Wang, 2023
Long term brain dynamics extend cognitive neuroscience to timescales relevant for health and physiology Darby M. Losey, 2023
Calibrated Conditional Density Models and Predictive Inference via Local Diagnostics David Zhao, 2023
Towards an Application-based Pipeline for Explainability Gregory Plumb, 2022
Objective Criteria for Explainable Machine Learning Chih-Kuan Yeh, 2022
Making Scientific Peer Review Scientific Ivan Stelmakh, 2022
Facets of regularization in high-dimensional learning: Cross-validation, risk monotonization, and model complexity Pratik Patil, 2022
Active Robot Perception using Programmable Light Curtains Siddharth Ancha, 2022
Strategies for Black-Box and Multi-Objective Optimization Biswajit Paria, 2022
Unifying State and Policy-Level Explanations for Reinforcement Learning Nicholay Topin, 2022
Sensor Fusion Frameworks for Nowcasting Maria Jahja, 2022
Equilibrium Approaches to Modern Deep Learning Shaojie Bai, 2022
Towards General Natural Language Understanding with Probabilistic Worldbuilding Abulhair Saparov, 2022
Applications of Point Process Modeling to Spiking Neurons (Unavailable) Yu Chen, 2021
Neural variability: structure, sources, control, and data augmentation Akash Umakantha, 2021
Structure and time course of neural population activity during learning Jay Hennig, 2021
Cross-view Learning with Limited Supervision Yao-Hung Hubert Tsai, 2021
Meta Reinforcement Learning through Memory Emilio Parisotto, 2021
Learning Embodied Agents with Scalably-Supervised Reinforcement Learning Lisa Lee, 2021
Learning to Predict and Make Decisions under Distribution Shift Yifan Wu, 2021
Statistical Game Theory Arun Sai Suggala, 2021
Towards Knowledge-capable AI: Agents that See, Speak, Act and Know Kenneth Marino, 2021
Learning and Reasoning with Fast Semidefinite Programming and Mixing Methods Po-Wei Wang, 2021
Bridging Language in Machines with Language in the Brain Mariya Toneva, 2021
Curriculum Learning Otilia Stretcu, 2021
Principles of Learning in Multitask Settings: A Probabilistic Perspective Maruan Al-Shedivat, 2021
Towards Robust and Resilient Machine Learning Adarsh Prasad, 2021
Towards Training AI Agents with All Types of Experiences: A Unified ML Formalism Zhiting Hu, 2021
Building Intelligent Autonomous Navigation Agents Devendra Chaplot, 2021
Learning to See by Moving: Self-supervising 3D Scene Representations for Perception, Control, and Visual Reasoning Hsiao-Yu Fish Tung, 2021
Statistical Astrophysics: From Extrasolar Planets to the Large-scale Structure of the Universe Collin Politsch, 2020
Causal Inference with Complex Data Structures and Non-Standard Effects Kwhangho Kim, 2020
Networks, Point Processes, and Networks of Point Processes Neil Spencer, 2020
Dissecting neural variability using population recordings, network models, and neurofeedback (Unavailable) Ryan Williamson, 2020
Predicting Health and Safety: Essays in Machine Learning for Decision Support in the Public Sector Dylan Fitzpatrick, 2020
Towards a Unified Framework for Learning and Reasoning Han Zhao, 2020
Learning DAGs with Continuous Optimization Xun Zheng, 2020
Machine Learning and Multiagent Preferences Ritesh Noothigattu, 2020
Learning and Decision Making from Diverse Forms of Information Yichong Xu, 2020
Towards Data-Efficient Machine Learning Qizhe Xie, 2020
Change modeling for understanding our world and the counterfactual one(s) William Herlands, 2020
Machine Learning in High-Stakes Settings: Risks and Opportunities Maria De-Arteaga, 2020
Data Decomposition for Constrained Visual Learning Calvin Murdock, 2020
Structured Sparse Regression Methods for Learning from High-Dimensional Genomic Data Micol Marchetti-Bowick, 2020
Towards Efficient Automated Machine Learning Liam Li, 2020
LEARNING COLLECTIONS OF FUNCTIONS Emmanouil Antonios Platanios, 2020
Provable, structured, and efficient methods for robustness of deep networks to adversarial examples Eric Wong , 2020
Reconstructing and Mining Signals: Algorithms and Applications Hyun Ah Song, 2020
Probabilistic Single Cell Lineage Tracing Chieh Lin, 2020
Graphical network modeling of phase coupling in brain activity (unavailable) Josue Orellana, 2019
Strategic Exploration in Reinforcement Learning - New Algorithms and Learning Guarantees Christoph Dann, 2019 Learning Generative Models using Transformations Chun-Liang Li, 2019
Estimating Probability Distributions and their Properties Shashank Singh, 2019
Post-Inference Methods for Scalable Probabilistic Modeling and Sequential Decision Making Willie Neiswanger, 2019
Accelerating Text-as-Data Research in Computational Social Science Dallas Card, 2019
Multi-view Relationships for Analytics and Inference Eric Lei, 2019
Information flow in networks based on nonstationary multivariate neural recordings Natalie Klein, 2019
Competitive Analysis for Machine Learning & Data Science Michael Spece, 2019
The When, Where and Why of Human Memory Retrieval Qiong Zhang, 2019
Towards Effective and Efficient Learning at Scale Adams Wei Yu, 2019
Towards Literate Artificial Intelligence Mrinmaya Sachan, 2019
Learning Gene Networks Underlying Clinical Phenotypes Under SNP Perturbations From Genome-Wide Data Calvin McCarter, 2019
Unified Models for Dynamical Systems Carlton Downey, 2019
Anytime Prediction and Learning for the Balance between Computation and Accuracy Hanzhang Hu, 2019
Statistical and Computational Properties of Some "User-Friendly" Methods for High-Dimensional Estimation Alnur Ali, 2019
Nonparametric Methods with Total Variation Type Regularization Veeranjaneyulu Sadhanala, 2019
New Advances in Sparse Learning, Deep Networks, and Adversarial Learning: Theory and Applications Hongyang Zhang, 2019
Gradient Descent for Non-convex Problems in Modern Machine Learning Simon Shaolei Du, 2019
Selective Data Acquisition in Learning and Decision Making Problems Yining Wang, 2019
Anomaly Detection in Graphs and Time Series: Algorithms and Applications Bryan Hooi, 2019
Neural dynamics and interactions in the human ventral visual pathway Yuanning Li, 2018
Tuning Hyperparameters without Grad Students: Scaling up Bandit Optimisation Kirthevasan Kandasamy, 2018
Teaching Machines to Classify from Natural Language Interactions Shashank Srivastava, 2018
Statistical Inference for Geometric Data Jisu Kim, 2018
Representation Learning @ Scale Manzil Zaheer, 2018
Diversity-promoting and Large-scale Machine Learning for Healthcare Pengtao Xie, 2018
Distribution and Histogram (DIsH) Learning Junier Oliva, 2018
Stress Detection for Keystroke Dynamics Shing-Hon Lau, 2018
Sublinear-Time Learning and Inference for High-Dimensional Models Enxu Yan, 2018
Neural population activity in the visual cortex: Statistical methods and application Benjamin Cowley, 2018
Efficient Methods for Prediction and Control in Partially Observable Environments Ahmed Hefny, 2018
Learning with Staleness Wei Dai, 2018
Statistical Approach for Functionally Validating Transcription Factor Bindings Using Population SNP and Gene Expression Data Jing Xiang, 2017
New Paradigms and Optimality Guarantees in Statistical Learning and Estimation Yu-Xiang Wang, 2017
Dynamic Question Ordering: Obtaining Useful Information While Reducing User Burden Kirstin Early, 2017
New Optimization Methods for Modern Machine Learning Sashank J. Reddi, 2017
Active Search with Complex Actions and Rewards Yifei Ma, 2017
Why Machine Learning Works George D. Montañez , 2017
Source-Space Analyses in MEG/EEG and Applications to Explore Spatio-temporal Neural Dynamics in Human Vision Ying Yang , 2017
Computational Tools for Identification and Analysis of Neuronal Population Activity Pengcheng Zhou, 2016
Expressive Collaborative Music Performance via Machine Learning Gus (Guangyu) Xia, 2016
Supervision Beyond Manual Annotations for Learning Visual Representations Carl Doersch, 2016
Exploring Weakly Labeled Data Across the Noise-Bias Spectrum Robert W. H. Fisher, 2016
Optimizing Optimization: Scalable Convex Programming with Proximal Operators Matt Wytock, 2016
Combining Neural Population Recordings: Theory and Application William Bishop, 2015
Discovering Compact and Informative Structures through Data Partitioning Madalina Fiterau-Brostean, 2015
Machine Learning in Space and Time Seth R. Flaxman, 2015
The Time and Location of Natural Reading Processes in the Brain Leila Wehbe, 2015
Shape-Constrained Estimation in High Dimensions Min Xu, 2015
Spectral Probabilistic Modeling and Applications to Natural Language Processing Ankur Parikh, 2015 Computational and Statistical Advances in Testing and Learning Aaditya Kumar Ramdas, 2015
Corpora and Cognition: The Semantic Composition of Adjectives and Nouns in the Human Brain Alona Fyshe, 2015
Learning Statistical Features of Scene Images Wooyoung Lee, 2014
Towards Scalable Analysis of Images and Videos Bin Zhao, 2014
Statistical Text Analysis for Social Science Brendan T. O'Connor, 2014
Modeling Large Social Networks in Context Qirong Ho, 2014
Semi-Cooperative Learning in Smart Grid Agents Prashant P. Reddy, 2013
On Learning from Collective Data Liang Xiong, 2013
Exploiting Non-sequence Data in Dynamic Model Learning Tzu-Kuo Huang, 2013
Mathematical Theories of Interaction with Oracles Liu Yang, 2013
Short-Sighted Probabilistic Planning Felipe W. Trevizan, 2013
Statistical Models and Algorithms for Studying Hand and Finger Kinematics and their Neural Mechanisms Lucia Castellanos, 2013
Approximation Algorithms and New Models for Clustering and Learning Pranjal Awasthi, 2013
Uncovering Structure in High-Dimensions: Networks and Multi-task Learning Problems Mladen Kolar, 2013
Learning with Sparsity: Structures, Optimization and Applications Xi Chen, 2013
GraphLab: A Distributed Abstraction for Large Scale Machine Learning Yucheng Low, 2013
Graph Structured Normal Means Inference James Sharpnack, 2013 (Joint Statistics & ML PhD)
Probabilistic Models for Collecting, Analyzing, and Modeling Expression Data Hai-Son Phuoc Le, 2013
Learning Large-Scale Conditional Random Fields Joseph K. Bradley, 2013
New Statistical Applications for Differential Privacy Rob Hall, 2013 (Joint Statistics & ML PhD)
Parallel and Distributed Systems for Probabilistic Reasoning Joseph Gonzalez, 2012
Spectral Approaches to Learning Predictive Representations Byron Boots, 2012
Attribute Learning using Joint Human and Machine Computation Edith L. M. Law, 2012
Statistical Methods for Studying Genetic Variation in Populations Suyash Shringarpure, 2012
Data Mining Meets HCI: Making Sense of Large Graphs Duen Horng (Polo) Chau, 2012
Learning with Limited Supervision by Input and Output Coding Yi Zhang, 2012
Target Sequence Clustering Benjamin Shih, 2011
Nonparametric Learning in High Dimensions Han Liu, 2010 (Joint Statistics & ML PhD)
Structural Analysis of Large Networks: Observations and Applications Mary McGlohon, 2010
Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy Brian D. Ziebart, 2010
Tractable Algorithms for Proximity Search on Large Graphs Purnamrita Sarkar, 2010
Rare Category Analysis Jingrui He, 2010
Coupled Semi-Supervised Learning Andrew Carlson, 2010
Fast Algorithms for Querying and Mining Large Graphs Hanghang Tong, 2009
Efficient Matrix Models for Relational Learning Ajit Paul Singh, 2009
Exploiting Domain and Task Regularities for Robust Named Entity Recognition Andrew O. Arnold, 2009
Theoretical Foundations of Active Learning Steve Hanneke, 2009
Generalized Learning Factors Analysis: Improving Cognitive Models with Machine Learning Hao Cen, 2009
Detecting Patterns of Anomalies Kaustav Das, 2009
Dynamics of Large Networks Jurij Leskovec, 2008
Computational Methods for Analyzing and Modeling Gene Regulation Dynamics Jason Ernst, 2008
Stacked Graphical Learning Zhenzhen Kou, 2007
Actively Learning Specific Function Properties with Applications to Statistical Inference Brent Bryan, 2007
Approximate Inference, Structure Learning and Feature Estimation in Markov Random Fields Pradeep Ravikumar, 2007
Scalable Graphical Models for Social Networks Anna Goldenberg, 2007
Measure Concentration of Strongly Mixing Processes with Applications Leonid Kontorovich, 2007
Tools for Graph Mining Deepayan Chakrabarti, 2005
Automatic Discovery of Latent Variable Models Ricardo Silva, 2005

- ODSC EUROPE
- AI+ Training
- Speak at ODSC

- Data Analytics
- Data Engineering
- Data Visualization
- Deep Learning
- Generative AI
- Machine Learning
- NLP and LLMs
- Business & Use Cases
- Career Advice
- Write for us
- ODSC Community Slack Channel
- Upcoming Webinars

10 Compelling Machine Learning Ph.D. Dissertations for 2020
Machine Learning Modeling Research posted by Daniel Gutierrez, ODSC August 19, 2020 Daniel Gutierrez, ODSC
As a data scientist, an integral part of my work in the field revolves around keeping current with research coming out of academia. I frequently scour arXiv.org for late-breaking papers that show trends and reveal fertile areas of research. Other sources of valuable research developments are in the form of Ph.D. dissertations, the culmination of a doctoral candidate’s work to confer his/her degree. Ph.D. candidates are highly motivated to choose research topics that establish new and creative paths toward discovery in their field of study. Their dissertations are highly focused on a specific problem. If you can find a dissertation that aligns with your areas of interest, consuming the research is an excellent way to do a deep dive into the technology. After reviewing hundreds of recent theses from universities all over the country, I present 10 machine learning dissertations that I found compelling in terms of my own areas of interest.
[Related article: Introduction to Bayesian Deep Learning ]
I hope you’ll find several that match your own fields of inquiry. Each thesis may take a while to consume but will result in hours of satisfying summer reading. Enjoy!
1. Bayesian Modeling and Variable Selection for Complex Data
As we routinely encounter high-throughput data sets in complex biological and environmental research, developing novel models and methods for variable selection has received widespread attention. This dissertation addresses a few key challenges in Bayesian modeling and variable selection for high-dimensional data with complex spatial structures.
2. Topics in Statistical Learning with a Focus on Large Scale Data
Big data vary in shape and call for different approaches. One type of big data is the tall data, i.e., a very large number of samples but not too many features. This dissertation describes a general communication-efficient algorithm for distributed statistical learning on this type of big data. The algorithm distributes the samples uniformly to multiple machines, and uses a common reference data to improve the performance of local estimates. The algorithm enables potentially much faster analysis, at a small cost to statistical performance.
Another type of big data is the wide data, i.e., too many features but a limited number of samples. It is also called high-dimensional data, to which many classical statistical methods are not applicable.
This dissertation discusses a method of dimensionality reduction for high-dimensional classification. The method partitions features into independent communities and splits the original classification problem into separate smaller ones. It enables parallel computing and produces more interpretable results.
3. Sets as Measures: Optimization and Machine Learning
The purpose of this machine learning dissertation is to address the following simple question:
How do we design efficient algorithms to solve optimization or machine learning problems where the decision variable (or target label) is a set of unknown cardinality?
Optimization and machine learning have proved remarkably successful in applications requiring the choice of single vectors. Some tasks, in particular many inverse problems, call for the design, or estimation, of sets of objects. When the size of these sets is a priori unknown, directly applying optimization or machine learning techniques designed for single vectors appears difficult. The work in this dissertation shows that a very old idea for transforming sets into elements of a vector space (namely, a space of measures), a common trick in theoretical analysis, generates effective practical algorithms.
4. A Geometric Perspective on Some Topics in Statistical Learning
Modern science and engineering often generate data sets with a large sample size and a comparably large dimension which puts classic asymptotic theory into question in many ways. Therefore, the main focus of this dissertation is to develop a fundamental understanding of statistical procedures for estimation and hypothesis testing from a non-asymptotic point of view, where both the sample size and problem dimension grow hand in hand. A range of different problems are explored in this thesis, including work on the geometry of hypothesis testing, adaptivity to local structure in estimation, effective methods for shape-constrained problems, and early stopping with boosting algorithms. The treatment of these different problems shares the common theme of emphasizing the underlying geometric structure.
5. Essays on Random Forest Ensembles
A random forest is a popular machine learning ensemble method that has proven successful in solving a wide range of classification problems. While other successful classifiers, such as boosting algorithms or neural networks, admit natural interpretations as maximum likelihood, a suitable statistical interpretation is much more elusive for a random forest. The first part of this dissertation demonstrates that a random forest is a fruitful framework in which to study AdaBoost and deep neural networks. The work explores the concept and utility of interpolation, the ability of a classifier to perfectly fit its training data. The second part of this dissertation places a random forest on more sound statistical footing by framing it as kernel regression with the proximity kernel. The work then analyzes the parameters that control the bandwidth of this kernel and discuss useful generalizations.
6. Marginally Interpretable Generalized Linear Mixed Models
A popular approach for relating correlated measurements of a non-Gaussian response variable to a set of predictors is to introduce latent random variables and fit a generalized linear mixed model. The conventional strategy for specifying such a model leads to parameter estimates that must be interpreted conditional on the latent variables. In many cases, interest lies not in these conditional parameters, but rather in marginal parameters that summarize the average effect of the predictors across the entire population. Due to the structure of the generalized linear mixed model, the average effect across all individuals in a population is generally not the same as the effect for an average individual. Further complicating matters, obtaining marginal summaries from a generalized linear mixed model often requires evaluation of an analytically intractable integral or use of an approximation. Another popular approach in this setting is to fit a marginal model using generalized estimating equations. This strategy is effective for estimating marginal parameters, but leaves one without a formal model for the data with which to assess quality of fit or make predictions for future observations. Thus, there exists a need for a better approach.
This dissertation defines a class of marginally interpretable generalized linear mixed models that leads to parameter estimates with a marginal interpretation while maintaining the desirable statistical properties of a conditionally specified model. The distinguishing feature of these models is an additive adjustment that accounts for the curvature of the link function and thereby preserves a specific form for the marginal mean after integrating out the latent random variables.
7. On the Detection of Hate Speech, Hate Speakers and Polarized Groups in Online Social Media
The objective of this dissertation is to explore the use of machine learning algorithms in understanding and detecting hate speech, hate speakers and polarized groups in online social media. Beginning with a unique typology for detecting abusive language, the work outlines the distinctions and similarities of different abusive language subtasks (offensive language, hate speech, cyberbullying and trolling) and how we might benefit from the progress made in each area. Specifically, the work suggests that each subtask can be categorized based on whether or not the abusive language being studied 1) is directed at a specific individual, or targets a generalized “Other” and 2) the extent to which the language is explicit versus implicit. The work then uses knowledge gained from this typology to tackle the “problem of offensive language” in hate speech detection.
8. Lasso Guarantees for Dependent Data
Serially correlated high dimensional data are prevalent in the big data era. In order to predict and learn the complex relationship among the multiple time series, high dimensional modeling has gained importance in various fields such as control theory, statistics, economics, finance, genetics and neuroscience. This dissertation studies a number of high dimensional statistical problems involving different classes of mixing processes.
9. Random forest robustness, variable importance, and tree aggregation
Random forest methodology is a nonparametric, machine learning approach capable of strong performance in regression and classification problems involving complex data sets. In addition to making predictions, random forests can be used to assess the relative importance of feature variables. This dissertation explores three topics related to random forests: tree aggregation, variable importance, and robustness.
10. Climate Data Computing: Optimal Interpolation, Averaging, Visualization and Delivery
This dissertation solves two important problems in the modern analysis of big climate data. The first is the efficient visualization and fast delivery of big climate data, and the second is a computationally extensive principal component analysis (PCA) using spherical harmonics on the Earth’s surface. The second problem creates a way to supply the data for the technology developed in the first. These two problems are computationally difficult, such as the representation of higher order spherical harmonics Y400, which is critical for upscaling weather data to almost infinitely fine spatial resolution.
I hope you enjoyed learning about these compelling machine learning dissertations.
Editor’s note: Interested in more data science research? Check out the Research Frontiers track at ODSC Europe this September 17-19 or the ODSC West Research Frontiers track this October 27-30.

Daniel Gutierrez, ODSC
Daniel D. Gutierrez is a practicing data scientist who’s been working with data long before the field came in vogue. As a technology journalist, he enjoys keeping a pulse on this fast-paced industry. Daniel is also an educator having taught data science, machine learning and R classes at the university level. He has authored four computer industry books on database and data science technology, including his most recent title, “Machine Learning and Data Science: An Introduction to Statistical Learning Methods with R.” Daniel holds a BS in Mathematics and Computer Science from UCLA.

Here are the First Sessions Coming to ODSC West 2024
West 2024 Conferences posted by ODSC Team Jun 20, 2024 We’re thrilled to introduce you to the leading experts and passionate data and AI practitioners who...

IMF Raises Alarm Over AI-Induced Labor Disruptions and Rising Inequality
AI and Data Science News posted by ODSC Team Jun 20, 2024 The International Monetary Fund (IMF) has expressed “profound concerns” regarding the massive labor disruptions and escalating...

Former OpenAI Co-founder Announces New Company Focused on safe development of “superintelligence”
AI and Data Science News posted by ODSC Team Jun 20, 2024 Ilya Sutskever, one of the founders of OpenAI, has announced the creation of a new company,...

Exploring 250+ Machine Learning Research Topics

In recent years, machine learning has become super popular and grown very quickly. This happened because technology got better, and there’s a lot more data available. Because of this, we’ve seen lots of new and amazing things happen in different areas. Machine learning research is what makes all these cool things possible. In this blog, we’ll talk about machine learning research topics, why they’re important, how you can pick one, what areas are popular to study, what’s new and exciting, the tough problems, and where you can find help if you want to be a researcher.
| Whether you’re delving into popular areas or tackling tough problems, our ‘ ‘ service is here to support your research journey.” |
Why Does Machine Learning Research Matter?
Table of Contents
Machine learning research is at the heart of the AI revolution. It underpins the development of intelligent systems capable of making predictions, automating tasks, and improving decision-making across industries. The importance of this research can be summarized as follows:
Advancements in Technology
The growth of machine learning research has led to the development of powerful algorithms, tools, and frameworks. Numerous industries, including healthcare, banking, autonomous cars, and natural language processing, have found use for these technology.
As researchers continue to push the boundaries of what’s possible, we can expect even more transformative technologies to emerge.
Real-world Applications
Machine learning research has brought about tangible changes in our daily lives. Voice assistants like Siri and Alexa, recommendation systems on streaming platforms, and personalized healthcare diagnostics are just a few examples of how this research impacts our world.
By working on new research topics, scientists can further refine these applications and create new ones.
Economic and Industrial Impacts
The economic implications of machine learning research are substantial. Companies that harness the power of machine learning gain a competitive edge in the market.
This creates a demand for skilled machine learning researchers, driving job opportunities and contributing to economic growth.
How to Choose the Machine Learning Research Topics?
Selecting the right machine learning research topics is crucial for your success as a machine learning researcher. Here’s a guide to help you make an informed decision:
- Understanding Your Interests
Start by considering your personal interests. Machine learning is a broad field with applications in virtually every sector. By choosing a topic that aligns with your passions, you’ll stay motivated and engaged throughout your research journey.
- Reviewing Current Trends
Stay updated on the latest trends in machine learning. Attend conferences, read research papers, and engage with the community to identify emerging research topics. Current trends often lead to exciting breakthroughs.
- Identifying Gaps in Existing Research
Sometimes, the most promising research topics involve addressing gaps in existing knowledge. These gaps may become evident through your own experiences, discussions with peers, or in the course of your studies.
- Collaborating with Experts
Collaboration is key in research. Working with experts in the field can help you refine your research topic and gain valuable insights. Seek mentors and collaborators who can guide you.
250+ Machine Learning Research Topics: Category-wise
Supervised learning.
- Explainable AI for Decision Support
- Few-shot Learning Methods
- Time Series Forecasting with Deep Learning
- Handling Imbalanced Datasets in Classification
- Regression Techniques for Non-linear Data
- Transfer Learning in Supervised Settings
- Multi-label Classification Strategies
- Semi-Supervised Learning Approaches
- Novel Feature Selection Methods
- Anomaly Detection in Supervised Scenarios
- Federated Learning for Distributed Supervised Models
- Ensemble Learning for Improved Accuracy
- Automated Hyperparameter Tuning
- Ethical Implications in Supervised Models
- Interpretability of Deep Neural Networks.
Unsupervised Learning
- Unsupervised Clustering of High-dimensional Data
- Semi-Supervised Clustering Approaches
- Density Estimation in Unsupervised Learning
- Anomaly Detection in Unsupervised Settings
- Transfer Learning for Unsupervised Tasks
- Representation Learning in Unsupervised Learning
- Outlier Detection Techniques
- Generative Models for Data Synthesis
- Manifold Learning in High-dimensional Spaces
- Unsupervised Feature Selection
- Privacy-Preserving Unsupervised Learning
- Community Detection in Complex Networks
- Clustering Interpretability and Visualization
- Unsupervised Learning for Image Segmentation
- Autoencoders for Dimensionality Reduction.
Reinforcement Learning
- Deep Reinforcement Learning in Real-world Applications
- Safe Reinforcement Learning for Autonomous Systems
- Transfer Learning in Reinforcement Learning
- Imitation Learning and Apprenticeship Learning
- Multi-agent Reinforcement Learning
- Explainable Reinforcement Learning Policies
- Hierarchical Reinforcement Learning
- Model-based Reinforcement Learning
- Curriculum Learning in Reinforcement Learning
- Reinforcement Learning in Robotics
- Exploration vs. Exploitation Strategies
- Reward Function Design and Ethical Considerations
- Reinforcement Learning in Healthcare
- Continuous Action Spaces in RL
- Reinforcement Learning for Resource Management.
Natural Language Processing (NLP)
- Multilingual and Cross-lingual NLP
- Contextualized Word Embeddings
- Bias Detection and Mitigation in NLP
- Named Entity Recognition for Low-resource Languages
- Sentiment Analysis in Social Media Text
- Dialogue Systems for Improved Customer Service
- Text Summarization for News Articles
- Low-resource Machine Translation
- Explainable NLP Models
- Coreference Resolution in NLP
- Question Answering in Specific Domains
- Detecting Fake News and Misinformation
- NLP for Healthcare: Clinical Document Understanding
- Emotion Analysis in Text
- Text Generation with Controlled Attributes.
Computer Vision
- Video Action Recognition and Event Detection
- Object Detection in Challenging Conditions (e.g., low light)
- Explainable Computer Vision Models
- Image Captioning for Accessibility
- Large-scale Image Retrieval
- Domain Adaptation in Computer Vision
- Fine-grained Image Classification
- Facial Expression Recognition
- Visual Question Answering
- Self-supervised Learning for Visual Representations
- Weakly Supervised Object Localization
- Human Pose Estimation in 3D
- Scene Understanding in Autonomous Vehicles
- Image Super-resolution
- Gaze Estimation for Human-Computer Interaction.
Deep Learning
- Neural Architecture Search for Efficient Models
- Self-attention Mechanisms and Transformers
- Interpretability in Deep Learning Models
- Robustness of Deep Neural Networks
- Generative Adversarial Networks (GANs) for Data Augmentation
- Neural Style Transfer in Art and Design
- Adversarial Attacks and Defenses
- Neural Networks for Audio and Speech Processing
- Explainable AI for Healthcare Diagnosis
- Automated Machine Learning (AutoML)
- Reinforcement Learning with Deep Neural Networks
- Model Compression and Quantization
- Lifelong Learning with Deep Learning Models
- Multimodal Learning with Vision and Language
- Federated Learning for Privacy-preserving Deep Learning.
Explainable AI
- Visualizing Model Decision Boundaries
- Saliency Maps and Feature Attribution
- Rule-based Explanations for Black-box Models
- Contrastive Explanations for Model Interpretability
- Counterfactual Explanations and What-if Analysis
- Human-centered AI for Explainable Healthcare
- Ethics and Fairness in Explainable AI
- Explanation Generation for Natural Language Processing
- Explainable AI in Financial Risk Assessment
- User-friendly Interfaces for Model Interpretability
- Scalability and Efficiency in Explainable Models
- Hybrid Models for Combined Accuracy and Explainability
- Post-hoc vs. Intrinsic Explanations
- Evaluation Metrics for Explanation Quality
- Explainable AI for Autonomous Vehicles.
Transfer Learning
- Zero-shot Learning and Few-shot Learning
- Cross-domain Transfer Learning
- Domain Adaptation for Improved Generalization
- Multilingual Transfer Learning in NLP
- Pretraining and Fine-tuning Techniques
- Lifelong Learning and Continual Learning
- Domain-specific Transfer Learning Applications
- Model Distillation for Knowledge Transfer
- Contrastive Learning for Transfer Learning
- Self-training and Pseudo-labeling
- Dynamic Adaption of Pretrained Models
- Privacy-Preserving Transfer Learning
- Unsupervised Domain Adaptation
- Negative Transfer Avoidance in Transfer Learning.
Federated Learning
- Secure Aggregation in Federated Learning
- Communication-efficient Federated Learning
- Privacy-preserving Techniques in Federated Learning
- Federated Transfer Learning
- Heterogeneous Federated Learning
- Real-world Applications of Federated Learning
- Federated Learning for Edge Devices
- Federated Learning for Healthcare Data
- Differential Privacy in Federated Learning
- Byzantine-robust Federated Learning
- Federated Learning with Non-IID Data
- Model Selection in Federated Learning
- Scalable Federated Learning for Large Datasets
- Client Selection and Sampling Strategies
- Global Model Update Synchronization in Federated Learning.
Quantum Machine Learning
- Quantum Neural Networks and Quantum Circuit Learning
- Quantum-enhanced Optimization for Machine Learning
- Quantum Data Compression and Quantum Principal Component Analysis
- Quantum Kernels and Quantum Feature Maps
- Quantum Variational Autoencoders
- Quantum Transfer Learning
- Quantum-inspired Classical Algorithms for ML
- Hybrid Quantum-Classical Models
- Quantum Machine Learning on Near-term Quantum Devices
- Quantum-inspired Reinforcement Learning
- Quantum Computing for Quantum Chemistry and Drug Discovery
- Quantum Machine Learning for Finance
- Quantum Data Structures and Quantum Databases
- Quantum-enhanced Cryptography in Machine Learning
- Quantum Generative Models and Quantum GANs.
Ethical AI and Bias Mitigation
- Fairness-aware Machine Learning Algorithms
- Bias Detection and Mitigation in Real-world Data
- Explainable AI for Ethical Decision Support
- Algorithmic Accountability and Transparency
- Privacy-preserving AI and Data Governance
- Ethical Considerations in AI for Healthcare
- Fairness in Recommender Systems
- Bias and Fairness in NLP Models
- Auditing AI Systems for Bias
- Societal Implications of AI in Criminal Justice
- Ethical AI Education and Training
- Bias Mitigation in Autonomous Vehicles
- Fair AI in Financial and Hiring Decisions
- Case Studies in Ethical AI Failures
- Legal and Policy Frameworks for Ethical AI.
Meta-Learning and AutoML
- Neural Architecture Search (NAS) for Efficient Models
- Transfer Learning in NAS
- Reinforcement Learning for NAS
- Multi-objective NAS
- Automated Data Augmentation
- Neural Architecture Optimization for Edge Devices
- Bayesian Optimization for AutoML
- Model Compression and Quantization in AutoML
- AutoML for Federated Learning
- AutoML in Healthcare Diagnostics
- Explainable AutoML
- Cost-sensitive Learning in AutoML
- AutoML for Small Data
- Human-in-the-Loop AutoML.
AI for Healthcare and Medicine
- Disease Prediction and Early Diagnosis
- Medical Image Analysis with Deep Learning
- Drug Discovery and Molecular Modeling
- Electronic Health Record Analysis
- Predictive Analytics in Healthcare
- Personalized Treatment Planning
- Healthcare Fraud Detection
- Telemedicine and Remote Patient Monitoring
- AI in Radiology and Pathology
- AI in Drug Repurposing
- AI for Medical Robotics and Surgery
- Genomic Data Analysis
- AI-powered Mental Health Assessment
- Explainable AI in Healthcare Decision Support
- AI in Epidemiology and Outbreak Prediction.
AI in Finance and Investment
- Algorithmic Trading and High-frequency Trading
- Credit Scoring and Risk Assessment
- Fraud Detection and Anti-money Laundering
- Portfolio Optimization with AI
- Financial Market Prediction
- Sentiment Analysis in Financial News
- Explainable AI in Financial Decision-making
- Algorithmic Pricing and Dynamic Pricing Strategies
- AI in Cryptocurrency and Blockchain
- Customer Behavior Analysis in Banking
- Explainable AI in Credit Decisioning
- AI in Regulatory Compliance
- Ethical AI in Financial Services
- AI for Real Estate Investment
- Automated Financial Reporting.
AI in Climate Change and Sustainability
- Climate Modeling and Prediction
- Renewable Energy Forecasting
- Smart Grid Optimization
- Energy Consumption Forecasting
- Carbon Emission Reduction with AI
- Ecosystem Monitoring and Preservation
- Precision Agriculture with AI
- AI for Wildlife Conservation
- Natural Disaster Prediction and Management
- Water Resource Management with AI
- Sustainable Transportation and Urban Planning
- Climate Change Mitigation Strategies with AI
- Environmental Impact Assessment with Machine Learning
- Eco-friendly Supply Chain Optimization
- Ethical AI in Climate-related Decision Support.
Data Privacy and Security
- Differential Privacy Mechanisms
- Federated Learning for Privacy-preserving AI
- Secure Multi-Party Computation
- Privacy-enhancing Technologies in Machine Learning
- Homomorphic Encryption for Machine Learning
- Ethical Considerations in Data Privacy
- Privacy-preserving AI in Healthcare
- AI for Secure Authentication and Access Control
- Blockchain and AI for Data Security
- Explainable Privacy in Machine Learning
- Privacy-preserving AI in Government and Public Services
- Privacy-compliant AI for IoT and Edge Devices
- Secure AI Models Sharing and Deployment
- Privacy-preserving AI in Financial Transactions
- AI in the Legal Frameworks of Data Privacy.
Global Collaboration in Research
- International Research Partnerships and Collaboration Models
- Multilingual and Cross-cultural AI Research
- Addressing Global Healthcare Challenges with AI
- Ethical Considerations in International AI Collaborations
- Interdisciplinary AI Research in Global Challenges
- AI Ethics and Human Rights in Global Research
- Data Sharing and Data Access in Global AI Research
- Cross-border Research Regulations and Compliance
- AI Innovation Hubs and International Research Centers
- AI Education and Training for Global Communities
- Humanitarian AI and AI for Sustainable Development Goals
- AI for Cultural Preservation and Heritage Protection
- Collaboration in AI-related Global Crises
- AI in Cross-cultural Communication and Understanding
- Global AI for Environmental Sustainability and Conservation.
Emerging Trends and Hot Topics in Machine Learning Research
The landscape of machine learning research topics is constantly evolving. Here are some of the emerging trends and hot topics that are shaping the field:
As AI systems become more prevalent, addressing ethical concerns and mitigating bias in algorithms are critical research areas.
Interpretable and Explainable Models
Understanding why machine learning models make specific decisions is crucial for their adoption in sensitive areas, such as healthcare and finance.
Meta-learning algorithms are designed to enable machines to learn how to learn, while AutoML aims to automate the machine learning process itself.
Machine learning is revolutionizing the healthcare sector, from diagnostic tools to drug discovery and patient care.
Algorithmic trading, risk assessment, and fraud detection are just a few applications of AI in finance, creating a wealth of research opportunities.
Machine learning research is crucial in analyzing and mitigating the impacts of climate change and promoting sustainable practices.
Challenges and Future Directions
While machine learning research has made tremendous strides, it also faces several challenges:
- Data Privacy and Security: As machine learning models require vast amounts of data, protecting individual privacy and data security are paramount concerns.
- Scalability and Efficiency: Developing efficient algorithms that can handle increasingly large datasets and complex computations remains a challenge.
- Ensuring Fairness and Transparency: Addressing bias in machine learning models and making their decisions transparent is essential for equitable AI systems.
- Quantum Computing and Machine Learning: The integration of quantum computing and machine learning has the potential to revolutionize the field, but it also presents unique challenges.
- Global Collaboration in Research: Machine learning research benefits from collaboration on a global scale. Ensuring that researchers from diverse backgrounds work together is vital for progress.
Resources for Machine Learning Researchers
If you’re looking to embark on a journey in machine learning research topics, there are various resources at your disposal:
- Journals and Conferences
Journals such as the “Journal of Machine Learning Research” and conferences like NeurIPS and ICML provide a platform for publishing and discussing research findings.
- Online Communities and Forums
Platforms like Stack Overflow, GitHub, and dedicated forums for machine learning provide spaces for collaboration and problem-solving.
- Datasets and Tools
Open-source datasets and tools like TensorFlow and PyTorch simplify the research process by providing access to data and pre-built models.
- Research Grants and Funding Opportunities
Many organizations and government agencies offer research grants and funding for machine learning projects. Seek out these opportunities to support your research.
Machine learning research is like a superhero in the world of technology. To be a part of this exciting journey, it’s important to choose the right machine learning research topics and keep up with the latest trends.
Machine learning research makes our lives better. It powers things like smart assistants and life-saving medical tools. It’s like the force driving the future of technology and society.
But, there are challenges too. We need to work together and be ethical in our research. Everyone should benefit from this technology. The future of machine learning research is incredibly bright. If you want to be a part of it, get ready for an exciting adventure. You can help create new solutions and make a big impact on the world.
Related Posts

Tips on How To Tackle A Machine Learning Project As A Beginner
Here in this blog, CodeAvail experts will explain to you tips on how to tackle a machine learning project as a beginner step by step…

Artificial Intelligence and Machine Learning Basics for Beginners
Here in this blog, CodeAvail experts will explain to you Artificial Intelligence and Machine Learning basics for beginners in detail step by step. What is…
- [email protected]
- +91-97 91 62 64 69
Thesis Topics for Machine Learning
Machine learning is one of the recently growing fields of research for classification, clustering, and prediction of input data . The techniques of ensembles and hybridization have contributed to the improvement of machine learning models . As a result, the speed of computation, operation, accuracy, and robustness of the machine learning models are enhanced. Through this article, you can get an overview of novel machine learning models, their design, performance, merits, and uses explained via a new taxonomic approach . Also, you can get all essential details regarding any thesis topics for machine learning from this page.
At present, there are many new ensembles and hybridized machine learning models being introduced and developed . Here the essentials of thesis writing are presented to you by our world-class certified writers and developers. What are the essential elements of a thesis statement?
- First of all you have to understand that thesis statement writing is the most crucial process which involves a lot of time and thinking
- Enough research data and evidence have to be gathered before writing a thesis statement
- The main Idea or the objective has to be presented clearly with supporting evidence
- Also remember that the thesis statement should be in accordance with the argument where adjustments are allowed
Usually, research scholars interact with our writers and experts for all aspects of thesis writing in machine learning. So we insist that you contact us much before you start your thesis so that you can have a clear-cut vision and well-strategized approach towards writing the best thesis.

Let us now have an idea about various headings to be included in any thesis topics for machine learning.
- Introduction – overview of the thesis
- Related / Existing works – presents of existing research
- Problems definition/statements – identify and highlight the problems
- Research methodology – convey the proposed concepts
- Results and Discussion – discuss the results of the proposed works with previous works
- Conclusion and future work – present the results of the proposed work
The introduction is the very first part of your thesis. It is the way by which you tend to create the first impression in the minds of the readers. What are the parts of the introduction in the thesis?
- The issue under examination is the core of an overview
- Main Idea and assertion has to be mentioned clearly
- Thesis statement and argument forms the fundamental aspect here
- Address the audience to prove to them that they are at the right place
- Scope of your paper should be mentioned satisfactorily
- The Planning based approach that you used to conduct research
In general, the choice of words, tone, approach, and language decide the quality of a thesis likewise the introduction. Our technical team and expert writers have gained enough experience writing thesis topics in machine learning. The amount of field knowledge and expertise that we gathered is quite large which will be of great use to you. Let us now talk about the next most important topic of a thesis called the issue
What are the guidelines for thesis writing?
Under the heading of the issue, the following aspects of research are to be included
- The background history about your result issue or concern solving which is stated as your objective
- The impact of the issue in this field
- Important characteristic features that affect the issue
- Potential research solutions that are undertaken for research
With the massive amount of reliable and authentic research materials that we provide, you can surely get all the necessary information to include in the issues part of your thesis. Also, our engineers and technical team are here to solve any kind of technical queries that you may get. Let us now talk about the literature review
LITERATURE REVIEW
- With important references and constructs from standard textbooks journals and relevant publications you need to make the following descriptions
- Relevant theory
- Issue explanation
- Potential solution
- Theoretical constructs
- Explanation on major theories
- Empirical literature from journal articles are considered for the following aspects
- Explanation on latest empirical studies
- Summary of the methodology adopted
- Important findings of the study
- Constraints associated with your findings
- The pathway of your research study has to be organized in line with the literature review to make keynotes on the following
- The referred definitions and concepts
- Unique aspects of the issues under examination
- Suitable method of your research
If you are searching for the best and most reliable online research guide for all kinds of thesis topics in machine learning then you are here at the right place. You can get professional and customized research support aligned with your institutional format from our experts. Let us now look into the method section in detail below
The following are the different aspects that you need to incorporate in the methods section of your thesis
- The research questions and issues under your examination
- Description of proposed works like data collection
- Rationale justification for the method of your choice
In addition to these aspects, you need to provide a clear description of all the research methods that you adopt in your study. For this purpose here are our research experts who will provide you with details on novel and innovative approaches useful for your research . You can also get concise and precise quantitative research data from us. Let us now look into this section of results
RESULTS AND DISCUSSION
On the page of results and discussion you need to incorporate the following aspects
- Description of major findings
- Visualization tools like charts, graphs, and tables to present the findings
- Relevant previous studies and results
- Creative and new results that you obtained
- Scopes to expand the previous studies with your findings
- Constraints of your study
The support of technical experts can help you do the best research work in machine learning . The interested researcher plus reliable and experienced research support makes the best PhD work possible. With our guidance, you get access to the best combo needed to carry out your research. Let’s now discuss the conclusions part
Conclusion and recommendation
In the part of conclusion, you need to include the following aspects
- Recap of issues being discussed
- Methods used and major findings
- Comparison between the original objective and accomplished results
- Scope for future expansion of your research
For each and every aspect of your machine learning PhD thesis , you can get complete support from our experts. In this respect let us now look to the topmost machine learning thesis topics below
Top 5 Thesis Topics for machine learning
- Machine learning is of great importance to physicians in the following perspectives
- Chatbots for speech recognition
- Pattern recognition for disease detection
- Treatment recommendation
- Detecting cancerous cells
- Body fluid analysis
- Identification of phenotypes in case of rare diseases
- Classifying data into groups for fault detection is possible using machine learning
- The following are some real-time examples for predictive analysis
- Fraudulent and legitimate transaction
- Improvement of prediction mechanism for detecting faults
- From the basics of developing products to predicting the stock market and real estate prices, predictive analytics is of greater importance
- Using a trading algorithm that makes use of a proper strategy for financing huge volumes of security is called statistical arbitrage
- Real-time examples of statistical arbitrage
- Analysis of huge data sets
- Algorithm-based trading for market microstructural analysis
- Real-time arbitrage possibilities
- Machine learning is used to enhance the strategy for statistical arbitrage as a result of which advanced results can be obtained
- In order to help the predictive analytics mechanisms to obtain increased accuracy feature extraction using machine learning plays a significant role
- Dataset annotations can be performed with greater significance using machine learning extraction methods where structured data can be extracted from unstructured information
- Real-time examples of machine learning-based feature extraction include the following
- Vocal cord disorder prediction
- Mechanism for prevention diagnosis and treatment of many disorders
- Detecting and solving many physiological problems in a Swift manner
- Extraction of critical information becomes easy with machine learning even when large volumes of data are being processed
- Machine learning methodologies can be used for translating speech into texts
- Recorded speech and real-time voice can be converted into text using machine learning systems designed for this purpose
- Speech can also be classified based on intensity, time, and frequency
- Voice search, appliance control, and voice dialing are the main real-time examples of speech recognition
In order to get confidential research guidance from world-class experts on all these thesis topics for machine learning, you can feel free to contact us. With more than 15 years of customer satisfaction, we are providing in-depth Research and advanced project support for all thesis topics for machine learning . Our thesis writing support also includes the following aspects
- Multiple revisions
- Complete grammatical check
- Formatting and editing
- Benchmark reference and citations from topmost journals
- Work privacy
- Internal review
We ensure all these criteria are conferred to you by world-class certified engineers, developers, and writers. So you can avail of our services with elevated confidence. We are here to support you fully. Let us now see some important machine learning methods in the following
Machine learning methods
Machine learning techniques are most often used in cases of making automatic decisions for any kind of input that they are trained and implemented for. Therefore machine learning approaches are expected to support the following aspects in decision making.
- Maximum accuracy of recommendations
- In-depth understanding and analysis before deciding to increase the trustworthiness
The decision-making approach using machine learning methods provides for higher accuracy in prediction and advanced comprehensible models respectively in implicit and explicit learning. For all your doubts and queries regarding the above-mentioned machine learning and decision-making approaches , you may feel free to contact us at any time of your convenience. Our technical team is highly experienced and skilled in resolving any kind of queries . Let us now see the important machine learning algorithms
Machine learning algorithms
Machine learning algorithms are very much diverse that they can be oriented into various objectives and goals for which machine learning methods are frequently adopted
- One rule, zero rule, and cubist
- RIPPER or Repeated Incremental Pruning to Produce Error Reduction
- Random forest, boosting, and AdaBoost
- Gradient Boosted Regression Trees and the Stacked Generalization
- Gradient Boosting Machines and Bootstrapped Aggregation
- Convolutional Neural Networks and Stacked Autoencoders
- Deep Boltzmann Machine and Deep Belief Networks
- Projection Pursuit and Sammon Mapping
- Principal Component Analysis and Partial Least Square Discriminant Analysis
- Quadratic Discriminant Analysis and Flexible Discriminant Analysis
- Partial Least Squares Regression and Multidimensional Scaling
- Principal Component Regression and Mixture Discriminant Analysis
- Regularized Discriminant Analysis and Linear Discriminant Analysis
- K means and K medians
- Expectation Maximization and Hierarchical Clustering
- Ridge Regression and Elastic Net
- Least Angle Regression and the LASSO or Least Absolute Shrinkage and Selection Operator
- Hopfield Network and perception
- Black Propagation and Radian Basis Function Network
- Naive Bayes and Bayesian Network
- Averaged One Dependents Estimators and Gaussian Naive Bayes
- Bayesian Belief Networks and Multinomial Naive Bayes
- Logistic, stepwise, and linear regression
- Locally Estimated Scatterplot Smoothing and Ordinary Least Squares Regression
- Multivariate Adaptive Regression Splines
- MS, C 4.5, C 5.0, and Decision stump
- Conditional Decision Trees and Iterative Dichotomiser 3
- Chi-squared Automatic Interaction Detection
- Classification and regression tree
- K Nearest Neighbour and Self Organising Map
- Locally Weighted Learning and Learning Vector Quantization
You can get a complete technical explanation and tips associated with the usage of these algorithms from our website. The selection of your thesis topic for machine learning becomes easier than before when you look into the various aspects of these algorithms and get to choose the best one based on your interests and needs. For this purpose, you can connect with us. We are here to assist you by giving proper expert consultation support for topic selection and allocating a highly qualified team of engineers to carry out your project successfully. Let us now talk about linear regression in detail
What is the process of linear regression?
The following are the three important stages in the process of linear regression analysis
- Data correlation and directionality analysis
- Model estimation based on linear fitting
- Estimation of validity and assessing the merits of the model
It is important that certain characteristic features are inherent in a model for the proper working of an algorithm. Feature engineering is the process by which essential features from raw data are obtained for the better functioning of an algorithm. With the most appropriate features extracted the algorithms become simple. Thus as a result accuracy of results is obtained even in the case of nonideal algorithms. What are the objectives of feature engineering?
- Preparation of input data for Better compatibility with the chosen machine learning algorithm
- Enhancement of the efficiency and working of machine learning models
With these goals, feature engineering becomes one of the important aspects of a machine learning research project. Talk to engineers for more details on the methods and algorithms used in extracting the necessary features. What are the techniques used in feature engineering?
- Imputation and binning
- Log transform and feature split
- Outliers handling and grouping functions
- One hot encoding and scaling
- Data extraction
Usually, we provide practical explanations in easy to understand words to our customers so that all their doubts are cleared even before they start their research. For this purpose, we make use of the real-time implemented models and our successful projects . Check out our website for all our machine learning project details. Let us now talk about hybrid machine learning models.
HYBRID MACHINE LEARNING MODELS
- When the machine learning methods are integrated with other methods such as optimization approaches, soft computing, and so on drastic improvement can be observed in the machine learning model.
- The ensemble methods are the culmination of grouping methods like boosting and bagging in case of multiple machine learning classifiers.
Our experts claim that the success of machine learning is dependent on ensemble and hybrid methods advancements. In this regard let us have a look into some of the hybrid methods below
- NBTree and functional tree
- Hybrid fuzzy with decision tree
- Logistic model tree and hybrid hoeffding tree
Most importantly these hybrid models and ensemble-based approaches in machine learning are on a rising scale and our technical team always stays updated about such novelties. So we are highly capable of providing you with the best support in all thesis topics for machine learning. Let us now look into the metrics used in analyzing the performance of machine learning models
Performance analysis of machine learning
Confusion metrics are prominently used for analyzing the machine learning models. The following are the fundamental terms associated with machine learning confusion metrics
- Contradiction of actual and predicted classes
- Correct prediction of negative values consisting of ‘no’ results for both actual and predicted classes
- Correct prediction of positive values consisting of ‘yes’ results for both actual and prediction classes
Using these fundamental parameters the essential values for calculation of efficiency and performance of the machine learning models are obtained as follows.
- Procession is considered as the ratio between the number of accurate positives predicted and the total number of positives claimed
- Recall is the ratio of all The true positive rate (in actual class being yes)
- F1 Score is the average between recall and precision hence taking into account all the false positives and false negatives
- Uneven distribution of classes require F1 Score to be evaluated than the accuracy, about which we will discuss below
- Accuracy can be considered in cases of similar false positives and false negatives.
- For different cost values of false positives and false negatives, it is recommended that you choose to recall and precision for performance evaluation
- Accuracy is the ratio between correct predictions and the total observations
- Also accuracy is considered as one of the most important and intuitive measures for analyzing the machine learning system performance
It becomes significant to note here that at thesis topics for machine learning ; our experts have produced excellent results in all these performance metrics. Contact our experts’ team for more details on the approaches that are considered to produce such the best outcomes . We work 24/7 to assist you.

Opening Hours
- Mon-Sat 09.00 am – 6.30 pm
- Lunch Time 12.30 pm – 01.30 pm
- Break Time 04.00 pm – 04.30 pm
- 18 years service excellence
- 40+ country reach
- 36+ university mou
- 194+ college mou
- 6000+ happy customers
- 100+ employees
- 240+ writers
- 60+ developers
- 45+ researchers
- 540+ Journal tieup
Payment Options

Our Clients

Social Links

- Terms of Use

Opening Time

Closing Time
- We follow Indian time zone


Kindson The Genius
Providing the best learning experience for professionals
10 Machine Learning Project (Thesis) Topics for 2020

Are you looking for some interesting project ideas for your thesis, project or dissertation? Then be sure that a machine learning topic would be a very good topic to write on. I have outlined 10 different topics. These topics are really good because you can easily obtain the dataset (i will provide the link to the dataset) and you can as well get some support from me. Let me know if you need any support in preparing your thesis.
You can leave a comment below in the comment area.

1. Machine Learning Model for Classification and Detection of Breast Cancer (Classification)
The data is provided by the Oncology department and details instances and related attributes which are nine in all.
You can obtain the dataset from here
2. Intelligent Internet Ads Generation (Classification)
This is one of the most interesting topics for me. The reason is because the revenue generated or expended by ads campaign depends not just on the volume of the ads, but also on the relevance of the ads. Therefore it is possible to increase revenue and reduce spending by developing a Machine Learning model that select relevants ads with a high level of accuracy. The dataset provides a collection of ads as well as the structure and geometry of the ads.
Get the ads dataset from here
3. Feature Extraction for National Census Data (Clustering)
This looks like big data stuff. But no! It’s simply dataset you can use for analysis. It is the actual data obtained from the US census in 1990. There are 68 attributes for each of the records and clustering would be performed to identify trends in the data.
You can obtain census the dataset from here
4. Movie Outcome Prediction (Classification)
This is quite a tasking project but its quite interesting. Before now, there exists models to predict the ratings of movies on a scale of 0 to 10 or 1 to 5. But this takes it a step further. You actually need to determine the outcome of the movie. The data set is a large multivariate dataset of movie director, cast, individual roles of the actor, remarks, studio and relevant documents.
You can get the movies dataset from here
5. Forest Fire Area Coverage Prediction (Regression)
This project have been classified as difficult but I don’t think so. The objective to predict the the area affected by forest fires. Dataset include relevant meteological information and other parameters taken from a region of Portugal.
You can get the fire dataset from here
6. Atmospheric Ozone Level Analysis and Detection (Clustering)
Two ground ozone datasets are provided for this. Data includes temperatures at various times of the day as well as wind speed. The data included in the dataset was collected in a span of 6 years from 1998 to 2004.
You can get the Ozone dataset from here
7. Crime Prediction in New York City (Regression)
If you have watched the movie, ‘Person of Interest’ directed by Jonathan Nolan, then you will appreciate the fact that there is a possibility of predicting violent criminal activities before they actually occur. Dataset would contain historical data on crime rate, types of crimes occurrence per region.
You can get the crime dataset from here
8. Sentiment Analysis on Amazon ECommerce User Reviews (Classification)
The dataset for this project is derived from user review comments from Amazon users. The model should be able to perform analysis on the training dataset and come up with a model that classifies the reviews based on sentiments. Granularity can be improved by generating predictions based on location and other factors.
You can get the reviews dataset from here
9. Home Eletrical Power Consumption Analysis (Regression)
Everyone uses electricity at home. Or rather, almost everyone! Would is not be great to have a system that helps to predict electricity consumption. Training dataset provided for this project includes feature set such as the size of the home, duration and more
You can get the dataset from here
10. Predictive Modelling of Individual Human Knowledge (Classification and Clustering)
Here the available dataset provide a collection of data about an individual on a subject matter. You are required to create a model that would try to quantify the amount of knowledge the individual have on the given subject. You can be creating by trying to also infer the performance of the user on certain exams.
I hope these 10 Machine Learning Project topic would be helpful to you.
Thanks for reading and do leave a comment below if you need some support

kindsonthegenius
Kindson Munonye is currently completing his doctoral program in Software Engineering in Budapest University of Technology and Economics
You might also like
Machine learning 101 – equation for a line and regression line, simple linear regression in machine learning (a simple tutorial), pca tutorial 1 – introduction to pca and dimensionality reduction, 2 thoughts on “ 10 machine learning project (thesis) topics for 2020 ”.
Is there any suggestion related to educational data mining?
I’m working on this. You can subscribe to my channel so when I make the update, you can get notified https://www.youtube.com/channel/UCvHgEAcw6VpcOA3864pSr5A
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
M.Tech/Ph.D Thesis Help in Chandigarh | Thesis Guidance in Chandigarh

+91-9465330425

Latest thesis topics in Machine Learning for research scholars:
Choosing a research and thesis topics in Machine Learning is the first choice of masters and Doctorate scholars now a days. Though, choosing and working on a thesis topic in machine learning is not an easy task as Machine learning uses certain statistical algorithms to make computers work in a certain way without being explicitly programmed. The algorithms receive an input value and predict an output for this by the use of certain statistical methods. The main aim of machine learning is to create intelligent machines which can think and work like human beings. Achieving the above mentioned goals is surely not very easy because of which students who choose research topic in machine learning face difficult challenges and require professional thesis help in their thesis work.
Below is the list of the latest thesis topics in Machine learning for research scholars:
- The classification technique for the face spoof detection in artificial neural networks using concepts of machine learning .
- The iris detection and reorganization system using classification and glcm algorithm in machine learning.
- Using machine learning algorithms in the detection of pattern system using algorithm of textual feature analysis and classification
- The plant disease detection using glcm and KNN classification in neural networks merged with the concepts of machine learning
- Using the algorithms of machine learning to propose technique for the prediction analysis in data mining
- The sentiment analysis technique using SVM classifier in data mining using machine learning approach
- The heart disease prediction using technique of classification in machine learning using the concepts of data mining.
So let’s start with machine learning.
First of all…
What exactly is machine learning?
Find the link at the end to download the latest topics for thesis and research in Machine Learning
What is Machine Learning?
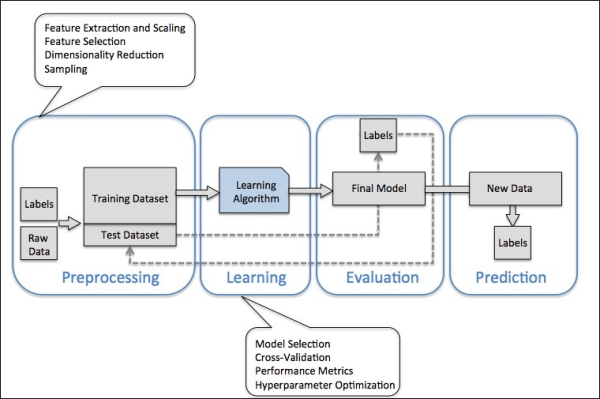
Machine Learning is a branch of artificial intelligence that gives systems the ability to learn automatically and improve themselves from the experience without being explicitly programmed or without the intervention of human. Its main aim is to make computers learn automatically from the experience.
Requirements of creating good machine learning systems
So what is required for creating such machine learning systems? Following are the things required in creating such machine learning systems:
Data – Input data is required for predicting the output.
Algorithms – Machine Learning is dependent on certain statistical algorithms to determine data patterns.
Automation – It is the ability to make systems operate automatically.
Iteration – The complete process is iterative i.e. repetition of process.
Scalability – The capacity of the machine can be increased or decreased in size and scale.
Modeling – The models are created according to the demand by the process of modeling.
Methods of Machine Learning
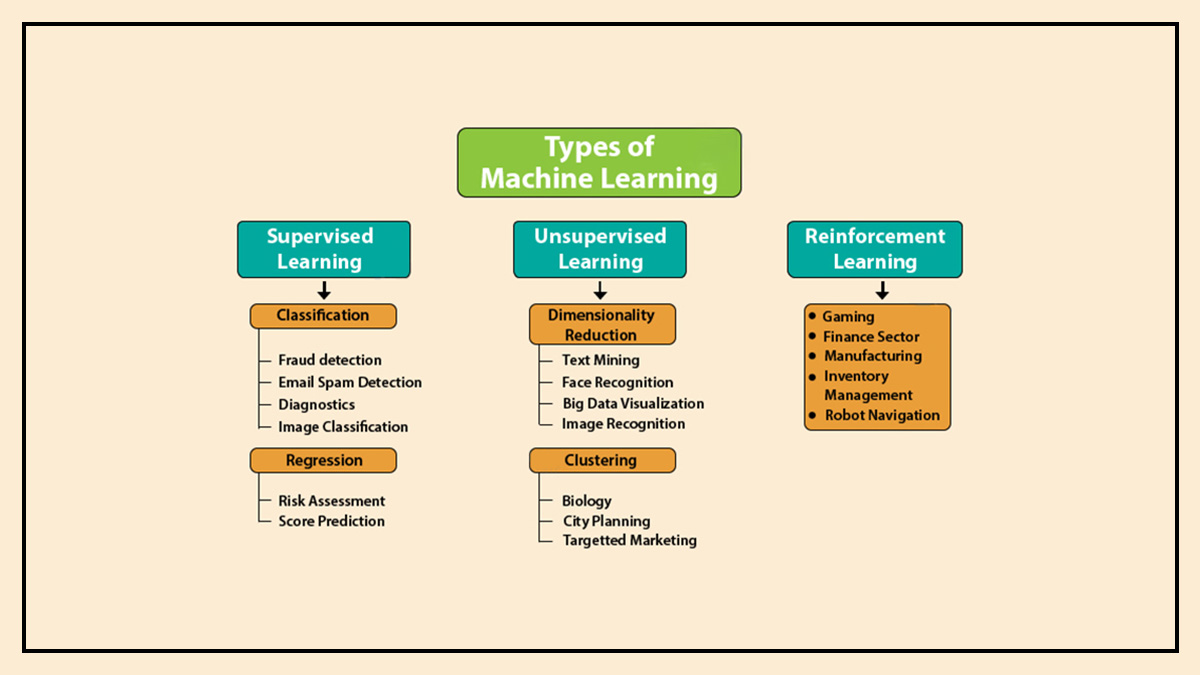
Machine Learning methods are classified into certain categories These are:
- Supervised Learning
- Unsupervised Learning
Reinforcement Learning
Supervised Learning – In this method, input and output is provided to the computer along with feedback during the training. The accuracy of predictions by the computer during training is also analyzed. The main goal of this training is to make computers learn how to map input to the output.
Unsupervised Learning – In this case, no such training is provided leaving computers to find the output on its own. Unsupervised learning is mostly applied on transactional data. It is used in more complex tasks. It uses another approach of iteration known as deep learning to arrive at some conclusions.
Reinforcement Learning – This type of learning uses three components namely – agent, environment, action. An agent is the one that perceives its surroundings, an environment is the one with which an agent interacts and acts in that environment. The main goal in reinforcement learning is to find the best possible policy.
How does machine learning work?
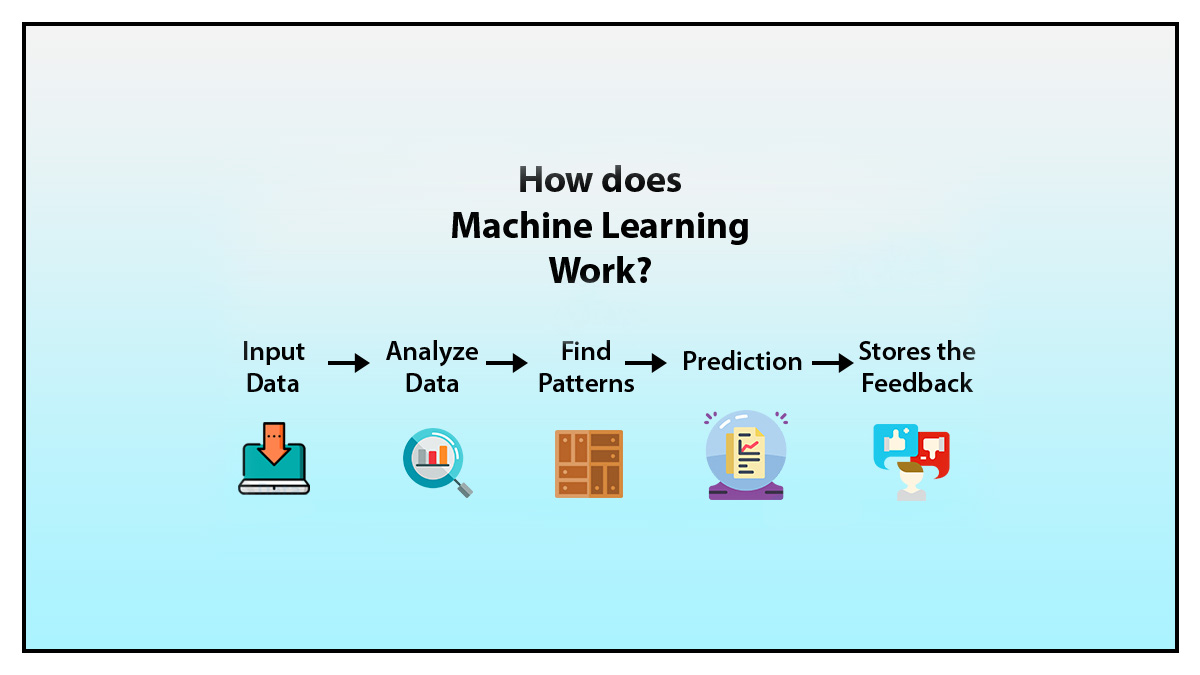
Machine learning makes use of processes similar to that of data mining. Machine learning algorithms are described in terms of target function(f) that maps input variable (x) to an output variable (y). This can be represented as:
There is also an error e which is the independent of the input variable x. Thus the more generalized form of the equation is:
In machine the mapping from x to y is done for predictions. This method is known as predictive modeling to make most accurate predictions. There are various assumptions for this function.
Benefits of Machine Learning

Everything is dependent on machine learning. Find out what are the benefits of machine learning.
Decision making is faster – Machine learning provides the best possible outcomes by prioritizing the routine decision-making processes.
Adaptability – Machine Learning provides the ability to adapt to new changing environment rapidly. The environment changes rapidly due to the fact that data is being constantly updated.
Innovation – Machine learning uses advanced algorithms that improve the overall decision-making capacity. This helps in developing innovative business services and models.
Insight – Machine learning helps in understanding unique data patterns and based on which specific actions can be taken.
Business growth – With machine learning overall business process and workflow will be faster and hence this would contribute to the overall business growth and acceleration.
Outcome will be good – With machine learning the quality of the outcome will be improved with lesser chances of error.
Branches of Machine Learning
- Computational Learning Theory
- Adversarial Machine Learning
- Quantum Machine Learning
- Robot Learning
- Meta-Learning
Computational Learning Theory – Computational learning theory is a subfield of machine learning for studying and analyzing the algorithms of machine learning. It is more or less similar to supervised learning.
Adversarial Machine Learning – Adversarial machine learning deals with the interaction of machine learning and computer security. The main aim of this technique is to look for safer methods in machine learning to prevent any form of spam and malware. It works on the following three principles:
Finding vulnerabilities in machine learning algorithms.
Devising strategies to check these potential vulnerabilities.
Implementing these preventive measures to improve the security of the algorithms.
Quantum Machine Learning – This area of machine learning deals with quantum physics. In this algorithm, the classical data set is translated into quantum computer for quantum information processing. It uses Grover’s search algorithm to solve unstructured search problems.
Predictive Analysis – Predictive Analysis uses statistical techniques from data modeling, machine learning and data mining to analyze current and historical data to predict the future. It extracts information from the given data. Customer relationship management(CRM) is the common application of predictive analysis.
Robot Learning – This area deals with the interaction of machine learning and robotics. It employs certain techniques to make robots to adapt to the surrounding environment through learning algorithms.
Grammar Induction – It is a process in machine learning to learn formal grammar from a given set of observations to identify characteristics of the observed model. Grammar induction can be done through genetic algorithms and greedy algorithms.
Meta-Learning – In this process learning algorithms are applied on meta-data and mainly deals with automatic learning algorithms.
Best Machine Learning Tools
Here is a list of artificial intelligence and machine learning tools for developers:
ai-one – It is a very good tool that provides software development kit for developers to implement artificial intelligence in an application.
Protege – It is a free and open-source framework and editor to build intelligent systems with the concept of ontology. It enables developers to create, upload and share applications.
IBM Watson – It is an open-API question answering system that answers questions asked in natural language. It has a collection of tools which can be used by developers and in business.
DiffBlue – It is another tool in artificial intelligence whose main objective is to locate bugs, errors and fix weaknesses in the code. All such things are done through automation.
TensorFlow – It is an open-source software library for machine learning. TensorFlow provides a library of numerical computations along with documentation, tutorials and other resources for support.
Amazon Web Services – Amazon has launched toolkits for developers along with applications which range from image interpretation to facial recognition.
OpenNN – It is an open-source, high-performance library for advanced analytics and is written in C++ programming language. It implements neural networks. It has a lot of tutorials and documentation along with an advanced tool known as Neural Designer.
Apache Spark – It is a framework for large-scale processing of data. It also provides a programming tool for deep learning on various machines.
Caffe – It is a framework for deep learning and is used in various industrial applications in the area of speech, vision and expression.
Veles – It is another deep learning platform written in C++ language and make use of python language for interaction between the nodes.
Machine Learning Applications
Following are some of the applications of machine learning:
Cognitive Services
Medical Services
Language Processing
Business Management
Image Recognition
Face Detection
Video Games
Computer Vision
Pattern Recognition
Machine Learning in Bioinformatics
Bioinformatics term is a combination of two terms bio, informatics. Bio means related to biology and informatics means information. Thus bioinformatics is a field that deals with processing and understanding of biological data using computational and statistical approach. Machine Learning has a number of applications in the area of bioinformatics. Machine Learning find its application in the following subfields of bioinformatics:
Genomics – Genomics is the study of DNA of organisms. Machine Learning systems can help in finding the location of protein-encoding genes in a DNA structure. Gene prediction is performed by using two types of searches named as extrinsic and intrinsic. Machine Learning is used in problems related to DNA alignment.
Proteomics – Proteomics is the study of proteins and amino acids. Proteomics is applied to problems related to proteins like protein side-chain prediction, protein modeling, and protein map prediction.
Microarrays – Microarrays are used to collect data about large biological materials. Machine learning can help in the data analysis, pattern prediction and genetic induction. It can also help in finding different types of cancer in genes.
System Biology – It deals with the interaction of biological components in the system. These components can be DNA, RNA, proteins and metabolites. Machine Learning help in modeling these interactions.
Text mining – Machine learning help in extraction of knowledge through natural language processing techniques.
Deep Learning
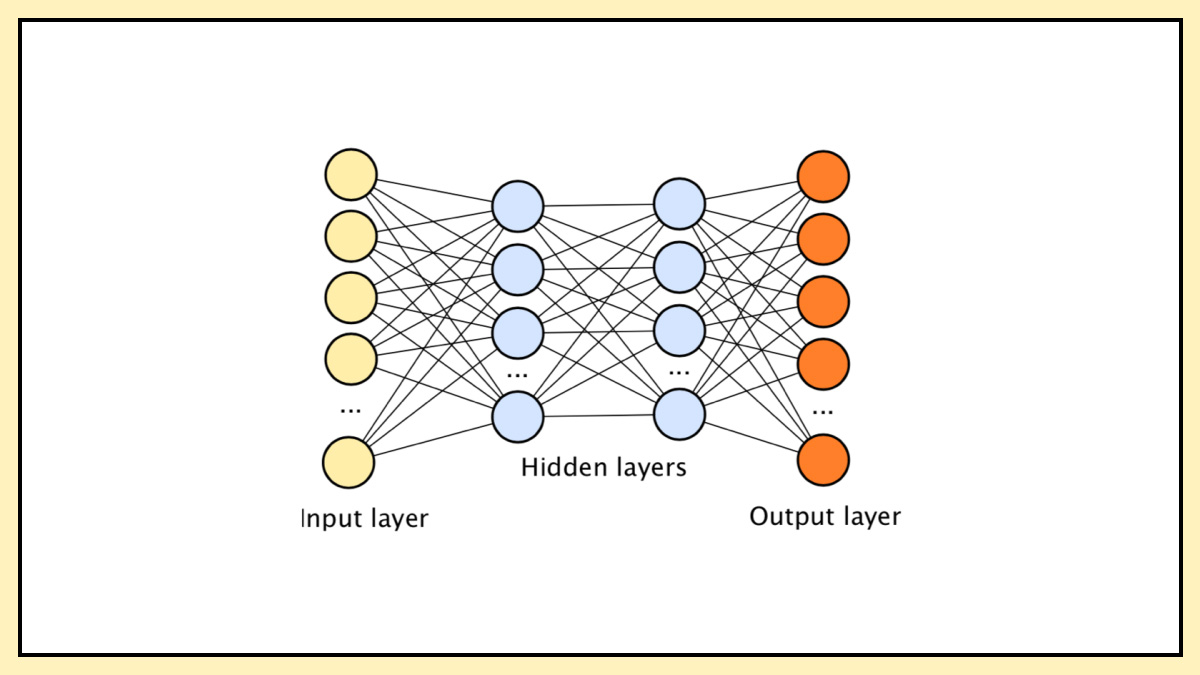
Deep Learning is a part of the broader field machine learning and is based on data representation learning. It is based on the interpretation of artificial neural network. Deep Learning algorithm uses many layers of processing. Each layer uses the output of previous layer as an input to itself. The algorithm used can be supervised algorithm or unsupervised algorithm. Deep Learning is mainly developed to handle complex mappings of input and output. It is another hot topic for M.Tech thesis and project along with machine learning.
Deep Neural Network
Deep Neural Network is a type of Artificial Neural Network with multiple layers which are hidden between the input layer and the output layer. This concept is known as feature hierarchy and it tends to increase the complexity and abstraction of data. This gives network the ability to handle very large, high-dimensional data sets having millions of parameters. The procedure of deep neural networks is as follows:
Consider some examples from a sample dataset.
Calculate error for this network.
Improve weight of the network to reduce the error.
Repeat the procedure.
Applications of Deep Learning
Here are some of the applications of Deep Learning:
Automatic Speech Recognition
Natural Language Processing
Customer Relationship Management
Bioinformatics
Mobile Advertising
Advantages of Deep Learning
Deep Learning helps in solving certain complex problems with high speed which were earlier left unsolved. Deep Learning is very useful in real world applications. Following are some of the main advantages of deep learning:
Eliminates unnecessary costs – Deep Learning helps to eliminate unnecessary costs by detecting defects and errors in the system.
Identifies defects which otherwise are difficult to detect – Deep Learning helps in identifying defects which left untraceable in the system.
Can inspect irregular shapes and patterns – Deep Learning can inspect irregular shapes and patterns which is difficult for machine learning to detect.
From this introduction, you must have known that why this topic is called as hot for your M.Tech thesis and projects. This was just the basic introduction to machine learning and deep learning. There is more to explore in these fields. You will get to know more once you start doing research on this topic for your M.Tech thesis. You can get thesis assistance and guidance on this topic from experts specialized in this field.
Research and Thesis Topics in Machine Learning
Here is the list of current research and thesis topics in Machine Learning :
Machine Learning Algorithms
Supervised Machine Learning
Unsupervised Machine Learning
Neural Networks
Predictive Learning
Bayesian Network
Data Mining
For starting with Machine Learning, you need to know some algorithms. Machine Learning algorithms are classified into three categories which provide the base for machine learning. These categories of algorithms are supervised learning, unsupervised learning, and reinforcement learning. The choice of algorithms depends upon the type of tasks you want to be done along with the type, quality, and nature of data present. The role of input data is crucial in machine learning algorithms.
Computer Vision is a field that deals with making systems that can read and interpret images. In simple terms, computer vision is a method of transmitting human intelligence and vision in machines. In computer vision, data is collected from images which are imparted to systems. The system will take action according to the information it interprets from what it sees.
It is a good topic for machine learning masters thesis. It is a type of machine learning algorithm in which makes predictions based on known data-sets. Input and output is provided to the system along with feedback. Supervised Learning is further classified into classification and regression problems. In the classification problem, the output is a category while in regression problem the output is a real value.
It is another category of machine learning algorithm in which input is known but the output is not known. Prior training is not provided to the system as in case of supervised learning. The main purpose of unsupervised learning is to model the underlying structure of data. Clustering and Association are the two types of unsupervised learning problems. k-means and Apriori algorithm are the examples of unsupervised learning algorithms.
Deep Learning is a hot topic in Machine Learning. It is already explained above. It is a part of the family of machine learning and deals with the functioning of the artificial neural network. Neural Networks are used to study the functioning of the human brain. It is one of the growing and exciting field. Deep learning has made it possible for the practical implementation of various machine learning applications.
Neural Networks are the systems to study the biological neural networks. It is an important application of machine learning and a good topic for masters thesis and research. The main purpose of Artificial Neural Network is to study how the human brain works. It finds its application in computer vision, speech recognition, machine translation etc. Artificial Neural Network is a collection of nodes which represent neurons.
Reinforcement Learning is a category of machine learning algorithms. Reinforcement Learning deals with software agents to study how these agents take actions in an environment in order to maximize their performance. Reinforcement Learning is different from supervised learning in the sense that correct input and output parameters are not provided.
Predictive Learning is another good topic for thesis in machine learning. In this technique, a model is built by an agent of its environment in which it performs actions. There is another field known as predictive analytics which is used to make predictions about future events which are unknown. For this, techniques like data mining, statistics, modeling, machine learning, and artificial intelligence are used.
It is a network that represents probabilistic relationships via Directed Acyclic Graph(DAG). There are algorithms in Bayesian Network for inference and learning. In the network, a probability function is there for each node which takes an input to give probability to the value associated with the node. Bayesian Network finds its application in bioinformatics, image processing, and computational biology.
Data Mining is the process of finding patterns from large data-sets to extract valuable information to make better decisions. It is a hot area of research. This technology use method from machine learning, statistics, and database systems for processing. There exist data mining techniques like clustering, association, decision trees, classification for the data mining process.
Click on the following link to download the latest thesis and research topics in Machine Learning
Latest Thesis and Research Topics on Machine Learning(pdf)
For more details Contact Us. You can call us on this number +91-9465330425 or drop an email at [email protected] for any type of dissertation help in India. You can also fill the query form on the website.
You can also visit our website Techsparks and follow us on Pinterest , Facebook , Twitter, YouTube and Linkedin for latest thesis blog.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Quick Enquiry
Get a quote, share your details to get free.
Google Custom Search
Wir verwenden Google für unsere Suche. Mit Klick auf „Suche aktivieren“ aktivieren Sie das Suchfeld und akzeptieren die Nutzungsbedingungen.
Hinweise zum Einsatz der Google Suche
- Data Analytics and Machine Learning Group
- TUM School of Computation, Information and Technology
- Technical University of Munich
Open Topics
We offer multiple Bachelor/Master theses, Guided Research projects and IDPs in the area of data mining/machine learning. A non-exhaustive list of open topics is listed below.
If you are interested in a thesis or a guided research project, please send your CV and transcript of records to Prof. Stephan Günnemann via email and we will arrange a meeting to talk about the potential topics.
Graph Neural Networks for Spatial Transcriptomics
Type: Master's Thesis
Prerequisites:
- Strong machine learning knowledge
- Proficiency with Python and deep learning frameworks (PyTorch, TensorFlow, JAX)
- Knowledge of graph neural networks (e.g., GCN, MPNN)
- Optional: Knowledge of bioinformatics and genomics
Description:
Spatial transcriptomics is a cutting-edge field at the intersection of genomics and spatial analysis, aiming to understand gene expression patterns within the context of tissue architecture. Our project focuses on leveraging graph neural networks (GNNs) to unlock the full potential of spatial transcriptomic data. Unlike traditional methods, GNNs can effectively capture the intricate spatial relationships between cells, enabling more accurate modeling and interpretation of gene expression dynamics across tissues. We seek motivated students to explore novel GNN architectures tailored for spatial transcriptomics, with a particular emphasis on addressing challenges such as spatial heterogeneity, cell-cell interactions, and spatially varying gene expression patterns.
Contact : Filippo Guerranti , Alessandro Palma
References:
- Cell clustering for spatial transcriptomics data with graph neural network
- Unsupervised spatially embedded deep representation of spatial transcriptomics
- SpaGCN: Integrating gene expression, spatial location and histology to identify spatial domains and spatially variable genes by graph convolutional network
- DeepST: identifying spatial domains in spatial transcriptomics by deep learning
- Deciphering spatial domains from spatially resolved transcriptomics with an adaptive graph attention auto-encoder
GCNG: graph convolutional networks for inferring gene interaction from spatial transcriptomics data
Generative Models for Drug Discovery
Type: Mater Thesis / Guided Research
- Proficiency with Python and deep learning frameworks (PyTorch or TensorFlow)
- Knowledge of graph neural networks (e.g. GCN, MPNN)
- No formal education in chemistry, physics or biology needed!
Effectively designing molecular geometries is essential to advancing pharmaceutical innovations, a domain which has experienced great attention through the success of generative models. These models promise a more efficient exploration of the vast chemical space and generation of novel compounds with specific properties by leveraging their learned representations, potentially leading to the discovery of molecules with unique properties that would otherwise go undiscovered. Our topics lie at the intersection of generative models like diffusion/flow matching models and graph representation learning, e.g., graph neural networks. The focus of our projects can be model development with an emphasis on downstream tasks ( e.g., diffusion guidance at inference time ) and a better understanding of the limitations of existing models.
Contact : Johanna Sommer , Leon Hetzel
Equivariant Diffusion for Molecule Generation in 3D
Equivariant Flow Matching with Hybrid Probability Transport for 3D Molecule Generation
Structure-based Drug Design with Equivariant Diffusion Models
Efficient Machine Learning: Pruning, Quantization, Distillation, and More
Type: Master's Thesis / Guided Research / Hiwi
- Strong knowledge in machine learning
- Proficiency with Python and deep learning frameworks (TensorFlow or PyTorch)
The efficiency of machine learning algorithms is commonly evaluated by looking at target performance, speed and memory footprint metrics. Reduce the costs associated to these metrics is of primary importance for real-world applications with limited ressources (e.g. embedded systems, real-time predictions). In this project, you will investigate solutions to improve the efficiency of machine leanring models by looking at multiple techniques like pruning, quantization, distillation, and more.
Contact: Bertrand Charpentier
- The Efficiency Misnomer
- A Gradient Flow Framework for Analyzing Network Pruning
- Distilling the Knowledge in a Neural Network
- A Survey of Quantization Methods for Efficient Neural Network Inference
Deep Generative Models
Type: Master Thesis / Guided Research
- Strong machine learning and probability theory knowledge
- Knowledge of generative models and their basics (e.g., Normalizing Flows, Diffusion Models, VAE)
- Optional: Neural ODEs/SDEs, Optimal Transport, Measure Theory
With recent advances, such as Diffusion Models, Transformers, Normalizing Flows, Flow Matching, etc., the field of generative models has gained significant attention in the machine learning and artificial intelligence research community. However, many problems and questions remain open, and the application to complex data domains such as graphs, time series, point processes, and sets is often non-trivial. We are interested in supervising motivated students to explore and extend the capabilities of state-of-the-art generative models for various data domains.
Contact : Marcel Kollovieh , David Lüdke
- Flow Matching for Generative Modeling
- Auto-Encoding Variational Bayes
- Denoising Diffusion Probabilistic Models
- Structured Denoising Diffusion Models in Discrete State-Spaces
Active Learning for Multi Agent 3D Object Detection
Type: Master's Thesis Industrial partner: BMW
Prerequisites:
- Strong knowledge in machine learning
- Knowledge in Object Detection
- Excellent programming skills
- Proficiency with Python and deep learning frameworks (TensorFlow or PyTorch)
Description:
In autonomous driving, state-of-the-art deep neural networks are used for perception tasks like for example 3D object detection. To provide promising results, these networks often require a lot of complex annotation data for training. These annotations are often costly and redundant. Active learning is used to select the most informative samples for annotation and cover a dataset with as less annotated data as possible.
The objective is to explore active learning approaches for 3D object detection using combined uncertainty and diversity based methods.
Contact: Sebastian Schmidt
References:
- Exploring Diversity-based Active Learning for 3D Object Detection in Autonomous Driving
- Efficient Uncertainty Estimation for Semantic Segmentation in Videos
- KECOR: Kernel Coding Rate Maximization for Active 3D Object Detection
- Towards Open World Active Learning for 3D Object Detection
Graph Neural Networks
Type: Master's thesis / Bachelor's thesis / guided research
- Knowledge of graph/network theory
Graph neural networks (GNNs) have recently achieved great successes in a wide variety of applications, such as chemistry, reinforcement learning, knowledge graphs, traffic networks, or computer vision. These models leverage graph data by updating node representations based on messages passed between nodes connected by edges, or by transforming node representation using spectral graph properties. These approaches are very effective, but many theoretical aspects of these models remain unclear and there are many possible extensions to improve GNNs and go beyond the nodes' direct neighbors and simple message aggregation.
Contact: Simon Geisler
- Semi-supervised classification with graph convolutional networks
- Relational inductive biases, deep learning, and graph networks
- Diffusion Improves Graph Learning
- Weisfeiler and leman go neural: Higher-order graph neural networks
- Reliable Graph Neural Networks via Robust Aggregation
Physics-aware Graph Neural Networks
Type: Master's thesis / guided research
- Proficiency with Python and deep learning frameworks (JAX or PyTorch)
- Knowledge of graph neural networks (e.g. GCN, MPNN, SchNet)
- Optional: Knowledge of machine learning on molecules and quantum chemistry
Deep learning models, especially graph neural networks (GNNs), have recently achieved great successes in predicting quantum mechanical properties of molecules. There is a vast amount of applications for these models, such as finding the best method of chemical synthesis or selecting candidates for drugs, construction materials, batteries, or solar cells. However, GNNs have only been proposed in recent years and there remain many open questions about how to best represent and leverage quantum mechanical properties and methods.
Contact: Nicholas Gao
- Directional Message Passing for Molecular Graphs
- Neural message passing for quantum chemistry
- Learning to Simulate Complex Physics with Graph Network
- Ab initio solution of the many-electron Schrödinger equation with deep neural networks
- Ab-Initio Potential Energy Surfaces by Pairing GNNs with Neural Wave Functions
- Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds
Robustness Verification for Deep Classifiers
Type: Master's thesis / Guided research
- Strong machine learning knowledge (at least equivalent to IN2064 plus an advanced course on deep learning)
- Strong background in mathematical optimization (preferably combined with Machine Learning setting)
- Proficiency with python and deep learning frameworks (Pytorch or Tensorflow)
- (Preferred) Knowledge of training techniques to obtain classifiers that are robust against small perturbations in data
Description : Recent work shows that deep classifiers suffer under presence of adversarial examples: misclassified points that are very close to the training samples or even visually indistinguishable from them. This undesired behaviour constraints possibilities of deployment in safety critical scenarios for promising classification methods based on neural nets. Therefore, new training methods should be proposed that promote (or preferably ensure) robust behaviour of the classifier around training samples.
Contact: Aleksei Kuvshinov
References (Background):
- Intriguing properties of neural networks
- Explaining and harnessing adversarial examples
- SoK: Certified Robustness for Deep Neural Networks
- Certified Adversarial Robustness via Randomized Smoothing
- Formal guarantees on the robustness of a classifier against adversarial manipulation
- Towards deep learning models resistant to adversarial attacks
- Provable defenses against adversarial examples via the convex outer adversarial polytope
- Certified defenses against adversarial examples
- Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks
Uncertainty Estimation in Deep Learning
Type: Master's Thesis / Guided Research
- Strong knowledge in probability theory
Safe prediction is a key feature in many intelligent systems. Classically, Machine Learning models compute output predictions regardless of the underlying uncertainty of the encountered situations. In contrast, aleatoric and epistemic uncertainty bring knowledge about undecidable and uncommon situations. The uncertainty view can be a substantial help to detect and explain unsafe predictions, and therefore make ML systems more robust. The goal of this project is to improve the uncertainty estimation in ML models in various types of task.
Contact: Tom Wollschläger , Dominik Fuchsgruber , Bertrand Charpentier
- Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift
- Predictive Uncertainty Estimation via Prior Networks
- Posterior Network: Uncertainty Estimation without OOD samples via Density-based Pseudo-Counts
- Evidential Deep Learning to Quantify Classification Uncertainty
- Weight Uncertainty in Neural Networks
Hierarchies in Deep Learning
Type: Master's Thesis / Guided Research
Multi-scale structures are ubiquitous in real life datasets. As an example, phylogenetic nomenclature naturally reveals a hierarchical classification of species based on their historical evolutions. Learning multi-scale structures can help to exhibit natural and meaningful organizations in the data and also to obtain compact data representation. The goal of this project is to leverage multi-scale structures to improve speed, performances and understanding of Deep Learning models.
Contact: Marcel Kollovieh , Bertrand Charpentier
- Tree Sampling Divergence: An Information-Theoretic Metricfor Hierarchical Graph Clustering
- Hierarchical Graph Representation Learning with Differentiable Pooling
- Gradient-based Hierarchical Clustering
- Gradient-based Hierarchical Clustering using Continuous Representations of Trees in Hyperbolic Space
- Advisers & Contacts
- Bachelor of Arts & Bachelor of Science in Engineering
- Prerequisites
- Declaring Computer Science for AB Students
- Declaring Computer Science for BSE Students
- Class of '25, '26 & '27 - Departmental Requirements
- Class of 2024 - Departmental Requirements
- COS126 Information
- Important Steps and Deadlines
- Independent Work Seminars
- Guidelines and Useful Information
Undergraduate Research Topics
- AB Junior Research Workshops
- Undergraduate Program FAQ
- Minor Program
- Funding for Student Group Activities
- Mailing Lists and Policies
- Study Abroad
- Jobs & Careers
- Admissions Requirements
- Breadth Requirements
- Pre-FPO Checklist
- FPO Checklist
- M.S.E. Track
- M.Eng. Track
- Departmental Internship Policy (for Master's students)
- General Examination
- Fellowship Opportunities
- Travel Reimbursement Policy
- Communication Skills
- Course Schedule
- Course Catalog
- Research Areas
- Interdisciplinary Programs
- Technical Reports
- Computing Facilities
- Researchers
- Technical Staff
- Administrative Staff
- Graduate Students
- Undergraduate Students
- Graduate Alumni
- Climate and Inclusion Committee
- Resources for Undergraduate & Graduate Students
- Outreach Initiatives
- Resources for Faculty & Staff
- Spotlight Stories
- Job Openings
- Undergraduate Program
- Independent Work & Theses
Suggested Undergraduate Research Topics

How to Contact Faculty for IW/Thesis Advising
Send the professor an e-mail. When you write a professor, be clear that you want a meeting regarding a senior thesis or one-on-one IW project, and briefly describe the topic or idea that you want to work on. Check the faculty listing for email addresses.
| *Updated April 9, 2024 | |||
| Table Legend: X = Available | N/A = Not Available | |||
| X | X | X | |
| X | X | X | |
| X | N/A | N/A | |
| X | X | X | |
| N/A | N/A | N/A | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | N/A | N/A | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | N/A | N/A | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| N/A | X | N/A | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| N/A | N/A | N/A | |
| X | X | X | |
| N/A | N/A | N/A | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| N/A | X | N/A | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | N/A | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
| X | X | X | |
Parastoo Abtahi, Room 419
Available for single-semester IW and senior thesis advising, 2024-2025
- Research Areas: Human-Computer Interaction (HCI), Augmented Reality (AR), and Spatial Computing
- Input techniques for on-the-go interaction (e.g., eye-gaze, microgestures, voice) with a focus on uncertainty, disambiguation, and privacy.
- Minimal and timely multisensory output (e.g., spatial audio, haptics) that enables users to attend to their physical environment and the people around them, instead of a 2D screen.
- Interaction with intelligent systems (e.g., IoT, robots) situated in physical spaces with a focus on updating users’ mental model despite the complexity and dynamicity of these systems.
Ryan Adams, Room 411
Research areas:
- Machine learning driven design
- Generative models for structured discrete objects
- Approximate inference in probabilistic models
- Accelerating solutions to partial differential equations
- Innovative uses of automatic differentiation
- Modeling and optimizing 3d printing and CNC machining
Andrew Appel, Room 209
Available for Fall 2024 IW advising, only
- Research Areas: Formal methods, programming languages, compilers, computer security.
- Software verification (for which taking COS 326 / COS 510 is helpful preparation)
- Game theory of poker or other games (for which COS 217 / 226 are helpful)
- Computer game-playing programs (for which COS 217 / 226)
- Risk-limiting audits of elections (for which ORF 245 or other knowledge of probability is useful)
Sanjeev Arora, Room 407
- Theoretical machine learning, deep learning and its analysis, natural language processing. My advisees would typically have taken a course in algorithms (COS423 or COS 521 or equivalent) and a course in machine learning.
- Show that finding approximate solutions to NP-complete problems is also NP-complete (i.e., come up with NP-completeness reductions a la COS 487).
- Experimental Algorithms: Implementing and Evaluating Algorithms using existing software packages.
- Studying/designing provable algorithms for machine learning and implementions using packages like scipy and MATLAB, including applications in Natural language processing and deep learning.
- Any topic in theoretical computer science.
David August, Room 221
Not available for IW or thesis advising, 2024-2025
- Research Areas: Computer Architecture, Compilers, Parallelism
- Containment-based approaches to security: We have designed and tested a simple hardware+software containment mechanism that stops incorrect communication resulting from faults, bugs, or exploits from leaving the system. Let's explore ways to use containment to solve real problems. Expect to work with corporate security and technology decision-makers.
- Parallelism: Studies show much more parallelism than is currently realized in compilers and architectures. Let's find ways to realize this parallelism.
- Any other interesting topic in computer architecture or compilers.
Mark Braverman, 194 Nassau St., Room 231
- Research Areas: computational complexity, algorithms, applied probability, computability over the real numbers, game theory and mechanism design, information theory.
- Topics in computational and communication complexity.
- Applications of information theory in complexity theory.
- Algorithms for problems under real-life assumptions.
- Game theory, network effects
- Mechanism design (could be on a problem proposed by the student)
Sebastian Caldas, 221 Nassau Street, Room 105
- Research Areas: collaborative learning, machine learning for healthcare. Typically, I will work with students that have taken COS324.
- Methods for collaborative and continual learning.
- Machine learning for healthcare applications.
Bernard Chazelle, 194 Nassau St., Room 301
- Research Areas: Natural Algorithms, Computational Geometry, Sublinear Algorithms.
- Natural algorithms (flocking, swarming, social networks, etc).
- Sublinear algorithms
- Self-improving algorithms
- Markov data structures
Danqi Chen, Room 412
- My advisees would be expected to have taken a course in machine learning and ideally have taken COS484 or an NLP graduate seminar.
- Representation learning for text and knowledge bases
- Pre-training and transfer learning
- Question answering and reading comprehension
- Information extraction
- Text summarization
- Any other interesting topics related to natural language understanding/generation
Marcel Dall'Agnol, Corwin 034
- Research Areas: Theoretical computer science. (Specifically, quantum computation, sublinear algorithms, complexity theory, interactive proofs and cryptography)
- Research Areas: Machine learning
Jia Deng, Room 423
- Research Areas: Computer Vision, Machine Learning.
- Object recognition and action recognition
- Deep Learning, autoML, meta-learning
- Geometric reasoning, logical reasoning
Adji Bousso Dieng, Room 406
- Research areas: Vertaix is a research lab at Princeton University led by Professor Adji Bousso Dieng. We work at the intersection of artificial intelligence (AI) and the natural sciences. The models and algorithms we develop are motivated by problems in those domains and contribute to advancing methodological research in AI. We leverage tools in statistical machine learning and deep learning in developing methods for learning with the data, of various modalities, arising from the natural sciences.
Robert Dondero, Corwin Hall, Room 038
- Research Areas: Software engineering; software engineering education.
- Develop or evaluate tools to facilitate student learning in undergraduate computer science courses at Princeton, and beyond.
- In particular, can code critiquing tools help students learn about software quality?
Zeev Dvir, 194 Nassau St., Room 250
- Research Areas: computational complexity, pseudo-randomness, coding theory and discrete mathematics.
- Independent Research: I have various research problems related to Pseudorandomness, Coding theory, Complexity and Discrete mathematics - all of which require strong mathematical background. A project could also be based on writing a survey paper describing results from a few theory papers revolving around some particular subject.
Benjamin Eysenbach, Room 416
- Research areas: reinforcement learning, machine learning. My advisees would typically have taken COS324.
- Using RL algorithms to applications in science and engineering.
- Emergent behavior of RL algorithms on high-fidelity robotic simulators.
- Studying how architectures and representations can facilitate generalization.
Christiane Fellbaum, 1-S-14 Green
- Research Areas: theoretical and computational linguistics, word sense disambiguation, lexical resource construction, English and multilingual WordNet(s), ontology
- Anything having to do with natural language--come and see me with/for ideas suitable to your background and interests. Some topics students have worked on in the past:
- Developing parsers, part-of-speech taggers, morphological analyzers for underrepresented languages (you don't have to know the language to develop such tools!)
- Quantitative approaches to theoretical linguistics questions
- Extensions and interfaces for WordNet (English and WN in other languages),
- Applications of WordNet(s), including:
- Foreign language tutoring systems,
- Spelling correction software,
- Word-finding/suggestion software for ordinary users and people with memory problems,
- Machine Translation
- Sentiment and Opinion detection
- Automatic reasoning and inferencing
- Collaboration with professors in the social sciences and humanities ("Digital Humanities")
Adam Finkelstein, Room 424
- Research Areas: computer graphics, audio.
Robert S. Fish, Corwin Hall, Room 037
- Networking and telecommunications
- Learning, perception, and intelligence, artificial and otherwise;
- Human-computer interaction and computer-supported cooperative work
- Online education, especially in Computer Science Education
- Topics in research and development innovation methodologies including standards, open-source, and entrepreneurship
- Distributed autonomous organizations and related blockchain technologies
Michael Freedman, Room 308
- Research Areas: Distributed systems, security, networking
- Projects related to streaming data analysis, datacenter systems and networks, untrusted cloud storage and applications. Please see my group website at http://sns.cs.princeton.edu/ for current research projects.
Ruth Fong, Room 032
- Research Areas: computer vision, machine learning, deep learning, interpretability, explainable AI, fairness and bias in AI
- Develop a technique for understanding AI models
- Design a AI model that is interpretable by design
- Build a paradigm for detecting and/or correcting failure points in an AI model
- Analyze an existing AI model and/or dataset to better understand its failure points
- Build a computer vision system for another domain (e.g., medical imaging, satellite data, etc.)
- Develop a software package for explainable AI
- Adapt explainable AI research to a consumer-facing problem
Note: I am happy to advise any project if there's a sufficient overlap in interest and/or expertise; please reach out via email to chat about project ideas.
Tom Griffiths, Room 405
Available for Fall 2024 single-semester IW advising, only
Research areas: computational cognitive science, computational social science, machine learning and artificial intelligence
Note: I am open to projects that apply ideas from computer science to understanding aspects of human cognition in a wide range of areas, from decision-making to cultural evolution and everything in between. For example, we have current projects analyzing chess game data and magic tricks, both of which give us clues about how human minds work. Students who have expertise or access to data related to games, magic, strategic sports like fencing, or other quantifiable domains of human behavior feel free to get in touch.
Aarti Gupta, Room 220
- Research Areas: Formal methods, program analysis, logic decision procedures
- Finding bugs in open source software using automatic verification tools
- Software verification (program analysis, model checking, test generation)
- Decision procedures for logical reasoning (SAT solvers, SMT solvers)
Elad Hazan, Room 409
- Research interests: machine learning methods and algorithms, efficient methods for mathematical optimization, regret minimization in games, reinforcement learning, control theory and practice
- Machine learning, efficient methods for mathematical optimization, statistical and computational learning theory, regret minimization in games.
- Implementation and algorithm engineering for control, reinforcement learning and robotics
- Implementation and algorithm engineering for time series prediction
Felix Heide, Room 410
- Research Areas: Computational Imaging, Computer Vision, Machine Learning (focus on Optimization and Approximate Inference).
- Optical Neural Networks
- Hardware-in-the-loop Holography
- Zero-shot and Simulation-only Learning
- Object recognition in extreme conditions
- 3D Scene Representations for View Generation and Inverse Problems
- Long-range Imaging in Scattering Media
- Hardware-in-the-loop Illumination and Sensor Optimization
- Inverse Lidar Design
- Phase Retrieval Algorithms
- Proximal Algorithms for Learning and Inference
- Domain-Specific Language for Optics Design
Peter Henderson , 302 Sherrerd Hall
- Research Areas: Machine learning, law, and policy
Kyle Jamieson, Room 306
- Research areas: Wireless and mobile networking; indoor radar and indoor localization; Internet of Things
- See other topics on my independent work ideas page (campus IP and CS dept. login req'd)
Alan Kaplan, 221 Nassau Street, Room 105
Research Areas:
- Random apps of kindness - mobile application/technology frameworks used to help individuals or communities; topic areas include, but are not limited to: first response, accessibility, environment, sustainability, social activism, civic computing, tele-health, remote learning, crowdsourcing, etc.
- Tools automating programming language interoperability - Java/C++, React Native/Java, etc.
- Software visualization tools for education
- Connected consumer devices, applications and protocols
Brian Kernighan, Room 311
- Research Areas: application-specific languages, document preparation, user interfaces, software tools, programming methodology
- Application-oriented languages, scripting languages.
- Tools; user interfaces
- Digital humanities
Zachary Kincaid, Room 219
- Research areas: programming languages, program analysis, program verification, automated reasoning
- Independent Research Topics:
- Develop a practical algorithm for an intractable problem (e.g., by developing practical search heuristics, or by reducing to, or by identifying a tractable sub-problem, ...).
- Design a domain-specific programming language, or prototype a new feature for an existing language.
- Any interesting project related to programming languages or logic.
Gillat Kol, Room 316
- Research area: theory
Aleksandra Korolova, 309 Sherrerd Hall
- Research areas: Societal impacts of algorithms and AI; privacy; fair and privacy-preserving machine learning; algorithm auditing.
Advisees typically have taken one or more of COS 226, COS 324, COS 423, COS 424 or COS 445.
Pravesh Kothari, Room 320
- Research areas: Theory
Amit Levy, Room 307
- Research Areas: Operating Systems, Distributed Systems, Embedded Systems, Internet of Things
- Distributed hardware testing infrastructure
- Second factor security tokens
- Low-power wireless network protocol implementation
- USB device driver implementation
Kai Li, Room 321
- Research Areas: Distributed systems; storage systems; content-based search and data analysis of large datasets.
- Fast communication mechanisms for heterogeneous clusters.
- Approximate nearest-neighbor search for high dimensional data.
- Data analysis and prediction of in-patient medical data.
- Optimized implementation of classification algorithms on manycore processors.
Xiaoyan Li, 221 Nassau Street, Room 104
- Research areas: Information retrieval, novelty detection, question answering, AI, machine learning and data analysis.
- Explore new statistical retrieval models for document retrieval and question answering.
- Apply AI in various fields.
- Apply supervised or unsupervised learning in health, education, finance, and social networks, etc.
- Any interesting project related to AI, machine learning, and data analysis.
Lydia Liu, Room 414
- Research Areas: algorithmic decision making, machine learning and society
- Theoretical foundations for algorithmic decision making (e.g. mathematical modeling of data-driven decision processes, societal level dynamics)
- Societal impacts of algorithms and AI through a socio-technical lens (e.g. normative implications of worst case ML metrics, prediction and model arbitrariness)
- Machine learning for social impact domains, especially education (e.g. responsible development and use of LLMs for education equity and access)
- Evaluation of human-AI decision making using statistical methods (e.g. causal inference of long term impact)
Wyatt Lloyd, Room 323
- Research areas: Distributed Systems
- Caching algorithms and implementations
- Storage systems
- Distributed transaction algorithms and implementations
Alex Lombardi , Room 312
- Research Areas: Theory
Margaret Martonosi, Room 208
- Quantum Computing research, particularly related to architecture and compiler issues for QC.
- Computer architectures specialized for modern workloads (e.g., graph analytics, machine learning algorithms, mobile applications
- Investigating security and privacy vulnerabilities in computer systems, particularly IoT devices.
- Other topics in computer architecture or mobile / IoT systems also possible.
Jonathan Mayer, Sherrerd Hall, Room 307
Available for Spring 2025 single-semester IW, only
- Research areas: Technology law and policy, with emphasis on national security, criminal procedure, consumer privacy, network management, and online speech.
- Assessing the effects of government policies, both in the public and private sectors.
- Collecting new data that relates to government decision making, including surveying current business practices and studying user behavior.
- Developing new tools to improve government processes and offer policy alternatives.
Mae Milano, Room 307
- Local-first / peer-to-peer systems
- Wide-ares storage systems
- Consistency and protocol design
- Type-safe concurrency
- Language design
- Gradual typing
- Domain-specific languages
- Languages for distributed systems
Andrés Monroy-Hernández, Room 405
- Research Areas: Human-Computer Interaction, Social Computing, Public-Interest Technology, Augmented Reality, Urban Computing
- Research interests:developing public-interest socio-technical systems. We are currently creating alternatives to gig work platforms that are more equitable for all stakeholders. For instance, we are investigating the socio-technical affordances necessary to support a co-op food delivery network owned and managed by workers and restaurants. We are exploring novel system designs that support self-governance, decentralized/federated models, community-centered data ownership, and portable reputation systems. We have opportunities for students interested in human-centered computing, UI/UX design, full-stack software development, and qualitative/quantitative user research.
- Beyond our core projects, we are open to working on research projects that explore the use of emerging technologies, such as AR, wearables, NFTs, and DAOs, for creative and out-of-the-box applications.
Christopher Moretti, Corwin Hall, Room 036
- Research areas: Distributed systems, high-throughput computing, computer science/engineering education
- Expansion, improvement, and evaluation of open-source distributed computing software.
- Applications of distributed computing for "big science" (e.g. biometrics, data mining, bioinformatics)
- Software and best practices for computer science education and study, especially Princeton's 126/217/226 sequence or MOOCs development
- Sports analytics and/or crowd-sourced computing
Radhika Nagpal, F316 Engineering Quadrangle
- Research areas: control, robotics and dynamical systems
Karthik Narasimhan, Room 422
- Research areas: Natural Language Processing, Reinforcement Learning
- Autonomous agents for text-based games ( https://www.microsoft.com/en-us/research/project/textworld/ )
- Transfer learning/generalization in NLP
- Techniques for generating natural language
- Model-based reinforcement learning
Arvind Narayanan, 308 Sherrerd Hall
Research Areas: fair machine learning (and AI ethics more broadly), the social impact of algorithmic systems, tech policy
Pedro Paredes, Corwin Hall, Room 041
My primary research work is in Theoretical Computer Science.
* Research Interest: Spectral Graph theory, Pseudorandomness, Complexity theory, Coding Theory, Quantum Information Theory, Combinatorics.
The IW projects I am interested in advising can be divided into three categories:
1. Theoretical research
I am open to advise work on research projects in any topic in one of my research areas of interest. A project could also be based on writing a survey given results from a few papers. Students should have a solid background in math (e.g., elementary combinatorics, graph theory, discrete probability, basic algebra/calculus) and theoretical computer science (226 and 240 material, like big-O/Omega/Theta, basic complexity theory, basic fundamental algorithms). Mathematical maturity is a must.
A (non exhaustive) list of topics of projects I'm interested in: * Explicit constructions of better vertex expanders and/or unique neighbor expanders. * Construction deterministic or random high dimensional expanders. * Pseudorandom generators for different problems. * Topics around the quantum PCP conjecture. * Topics around quantum error correcting codes and locally testable codes, including constructions, encoding and decoding algorithms.
2. Theory informed practical implementations of algorithms Very often the great advances in theoretical research are either not tested in practice or not even feasible to be implemented in practice. Thus, I am interested in any project that consists in trying to make theoretical ideas applicable in practice. This includes coming up with new algorithms that trade some theoretical guarantees for feasible implementation yet trying to retain the soul of the original idea; implementing new algorithms in a suitable programming language; and empirically testing practical implementations and comparing them with benchmarks / theoretical expectations. A project in this area doesn't have to be in my main areas of research, any theoretical result could be suitable for such a project.
Some examples of areas of interest: * Streaming algorithms. * Numeric linear algebra. * Property testing. * Parallel / Distributed algorithms. * Online algorithms. 3. Machine learning with a theoretical foundation
I am interested in projects in machine learning that have some mathematical/theoretical, even if most of the project is applied. This includes topics like mathematical optimization, statistical learning, fairness and privacy.
One particular area I have been recently interested in is in the area of rating systems (e.g., Chess elo) and applications of this to experts problems.
Final Note: I am also willing to advise any project with any mathematical/theoretical component, even if it's not the main one; please reach out via email to chat about project ideas.
Iasonas Petras, Corwin Hall, Room 033
- Research Areas: Information Based Complexity, Numerical Analysis, Quantum Computation.
- Prerequisites: Reasonable mathematical maturity. In case of a project related to Quantum Computation a certain familiarity with quantum mechanics is required (related courses: ELE 396/PHY 208).
- Possible research topics include:
1. Quantum algorithms and circuits:
- i. Design or simulation quantum circuits implementing quantum algorithms.
- ii. Design of quantum algorithms solving/approximating continuous problems (such as Eigenvalue problems for Partial Differential Equations).
2. Information Based Complexity:
- i. Necessary and sufficient conditions for tractability of Linear and Linear Tensor Product Problems in various settings (for example worst case or average case).
- ii. Necessary and sufficient conditions for tractability of Linear and Linear Tensor Product Problems under new tractability and error criteria.
- iii. Necessary and sufficient conditions for tractability of Weighted problems.
- iv. Necessary and sufficient conditions for tractability of Weighted Problems under new tractability and error criteria.
3. Topics in Scientific Computation:
- i. Randomness, Pseudorandomness, MC and QMC methods and their applications (Finance, etc)
Yuri Pritykin, 245 Carl Icahn Lab
- Research interests: Computational biology; Cancer immunology; Regulation of gene expression; Functional genomics; Single-cell technologies.
- Potential research projects: Development, implementation, assessment and/or application of algorithms for analysis, integration, interpretation and visualization of multi-dimensional data in molecular biology, particularly single-cell and spatial genomics data.
Benjamin Raphael, Room 309
- Research interests: Computational biology and bioinformatics; Cancer genomics; Algorithms and machine learning approaches for analysis of large-scale datasets
- Implementation and application of algorithms to infer evolutionary processes in cancer
- Identifying correlations between combinations of genomic mutations in human and cancer genomes
- Design and implementation of algorithms for genome sequencing from new DNA sequencing technologies
- Graph clustering and network anomaly detection, particularly using diffusion processes and methods from spectral graph theory
Vikram Ramaswamy, 035 Corwin Hall
- Research areas: Interpretability of AI systems, Fairness in AI systems, Computer vision.
- Constructing a new method to explain a model / create an interpretable by design model
- Analyzing a current model / dataset to understand bias within the model/dataset
- Proposing new fairness evaluations
- Proposing new methods to train to improve fairness
- Developing synthetic datasets for fairness / interpretability benchmarks
- Understanding robustness of models
Ran Raz, Room 240
- Research Area: Computational Complexity
- Independent Research Topics: Computational Complexity, Information Theory, Quantum Computation, Theoretical Computer Science
Szymon Rusinkiewicz, Room 406
- Research Areas: computer graphics; computer vision; 3D scanning; 3D printing; robotics; documentation and visualization of cultural heritage artifacts
- Research ways of incorporating rotation invariance into computer visiontasks such as feature matching and classification
- Investigate approaches to robust 3D scan matching
- Model and compensate for imperfections in 3D printing
- Given a collection of small mobile robots, apply control policies learned in simulation to the real robots.
Olga Russakovsky, Room 408
- Research Areas: computer vision, machine learning, deep learning, crowdsourcing, fairness&bias in AI
- Design a semantic segmentation deep learning model that can operate in a zero-shot setting (i.e., recognize and segment objects not seen during training)
- Develop a deep learning classifier that is impervious to protected attributes (such as gender or race) that may be erroneously correlated with target classes
- Build a computer vision system for the novel task of inferring what object (or part of an object) a human is referring to when pointing to a single pixel in the image. This includes both collecting an appropriate dataset using crowdsourcing on Amazon Mechanical Turk, creating a new deep learning formulation for this task, and running extensive analysis of both the data and the model
Sebastian Seung, Princeton Neuroscience Institute, Room 153
- Research Areas: computational neuroscience, connectomics, "deep learning" neural networks, social computing, crowdsourcing, citizen science
- Gamification of neuroscience (EyeWire 2.0)
- Semantic segmentation and object detection in brain images from microscopy
- Computational analysis of brain structure and function
- Neural network theories of brain function
Jaswinder Pal Singh, Room 324
- Research Areas: Boundary of technology and business/applications; building and scaling technology companies with special focus at that boundary; parallel computing systems and applications: parallel and distributed applications and their implications for software and architectural design; system software and programming environments for multiprocessors.
- Develop a startup company idea, and build a plan/prototype for it.
- Explore tradeoffs at the boundary of technology/product and business/applications in a chosen area.
- Study and develop methods to infer insights from data in different application areas, from science to search to finance to others.
- Design and implement a parallel application. Possible areas include graphics, compression, biology, among many others. Analyze performance bottlenecks using existing tools, and compare programming models/languages.
- Design and implement a scalable distributed algorithm.
Mona Singh, Room 420
- Research Areas: computational molecular biology, as well as its interface with machine learning and algorithms.
- Whole and cross-genome methods for predicting protein function and protein-protein interactions.
- Analysis and prediction of biological networks.
- Computational methods for inferring specific aspects of protein structure from protein sequence data.
- Any other interesting project in computational molecular biology.
Robert Tarjan, 194 Nassau St., Room 308
- Research Areas: Data structures; graph algorithms; combinatorial optimization; computational complexity; computational geometry; parallel algorithms.
- Implement one or more data structures or combinatorial algorithms to provide insight into their empirical behavior.
- Design and/or analyze various data structures and combinatorial algorithms.
Olga Troyanskaya, Room 320
- Research Areas: Bioinformatics; analysis of large-scale biological data sets (genomics, gene expression, proteomics, biological networks); algorithms for integration of data from multiple data sources; visualization of biological data; machine learning methods in bioinformatics.
- Implement and evaluate one or more gene expression analysis algorithm.
- Develop algorithms for assessment of performance of genomic analysis methods.
- Develop, implement, and evaluate visualization tools for heterogeneous biological data.
David Walker, Room 211
- Research Areas: Programming languages, type systems, compilers, domain-specific languages, software-defined networking and security
- Independent Research Topics: Any other interesting project that involves humanitarian hacking, functional programming, domain-specific programming languages, type systems, compilers, software-defined networking, fault tolerance, language-based security, theorem proving, logic or logical frameworks.
Shengyi Wang, Postdoctoral Research Associate, Room 216
Available for Fall 2024 single-semester IW, only
- Independent Research topics: Explore Escher-style tilings using (introductory) group theory and automata theory to produce beautiful pictures.
Kevin Wayne, Corwin Hall, Room 040
- Research Areas: design, analysis, and implementation of algorithms; data structures; combinatorial optimization; graphs and networks.
- Design and implement computer visualizations of algorithms or data structures.
- Develop pedagogical tools or programming assignments for the computer science curriculum at Princeton and beyond.
- Develop assessment infrastructure and assessments for MOOCs.
Matt Weinberg, 194 Nassau St., Room 222
- Research Areas: algorithms, algorithmic game theory, mechanism design, game theoretical problems in {Bitcoin, networking, healthcare}.
- Theoretical questions related to COS 445 topics such as matching theory, voting theory, auction design, etc.
- Theoretical questions related to incentives in applications like Bitcoin, the Internet, health care, etc. In a little bit more detail: protocols for these systems are often designed assuming that users will follow them. But often, users will actually be strictly happier to deviate from the intended protocol. How should we reason about user behavior in these protocols? How should we design protocols in these settings?
Huacheng Yu, Room 310
- data structures
- streaming algorithms
- design and analyze data structures / streaming algorithms
- prove impossibility results (lower bounds)
- implement and evaluate data structures / streaming algorithms
Ellen Zhong, Room 314
Opportunities outside the department.
We encourage students to look in to doing interdisciplinary computer science research and to work with professors in departments other than computer science. However, every CS independent work project must have a strong computer science element (even if it has other scientific or artistic elements as well.) To do a project with an adviser outside of computer science you must have permission of the department. This can be accomplished by having a second co-adviser within the computer science department or by contacting the independent work supervisor about the project and having he or she sign the independent work proposal form.
Here is a list of professors outside the computer science department who are eager to work with computer science undergraduates.
Maria Apostolaki, Engineering Quadrangle, C330
- Research areas: Computing & Networking, Data & Information Science, Security & Privacy
Branko Glisic, Engineering Quadrangle, Room E330
- Documentation of historic structures
- Cyber physical systems for structural health monitoring
- Developing virtual and augmented reality applications for documenting structures
- Applying machine learning techniques to generate 3D models from 2D plans of buildings
- Contact : Rebecca Napolitano, rkn2 (@princeton.edu)
Mihir Kshirsagar, Sherrerd Hall, Room 315
Center for Information Technology Policy.
- Consumer protection
- Content regulation
- Competition law
- Economic development
- Surveillance and discrimination
Sharad Malik, Engineering Quadrangle, Room B224
Select a Senior Thesis Adviser for the 2020-21 Academic Year.
- Design of reliable hardware systems
- Verifying complex software and hardware systems
Prateek Mittal, Engineering Quadrangle, Room B236
- Internet security and privacy
- Social Networks
- Privacy technologies, anonymous communication
- Network Science
- Internet security and privacy: The insecurity of Internet protocols and services threatens the safety of our critical network infrastructure and billions of end users. How can we defend end users as well as our critical network infrastructure from attacks?
- Trustworthy social systems: Online social networks (OSNs) such as Facebook, Google+, and Twitter have revolutionized the way our society communicates. How can we leverage social connections between users to design the next generation of communication systems?
- Privacy Technologies: Privacy on the Internet is eroding rapidly, with businesses and governments mining sensitive user information. How can we protect the privacy of our online communications? The Tor project (https://www.torproject.org/) is a potential application of interest.
Ken Norman, Psychology Dept, PNI 137
- Research Areas: Memory, the brain and computation
- Lab: Princeton Computational Memory Lab
Potential research topics
- Methods for decoding cognitive state information from neuroimaging data (fMRI and EEG)
- Neural network simulations of learning and memory
Caroline Savage
Office of Sustainability, Phone:(609)258-7513, Email: cs35 (@princeton.edu)
The Campus as Lab program supports students using the Princeton campus as a living laboratory to solve sustainability challenges. The Office of Sustainability has created a list of campus as lab research questions, filterable by discipline and topic, on its website .
An example from Computer Science could include using TigerEnergy , a platform which provides real-time data on campus energy generation and consumption, to study one of the many energy systems or buildings on campus. Three CS students used TigerEnergy to create a live energy heatmap of campus .
Other potential projects include:
- Apply game theory to sustainability challenges
- Develop a tool to help visualize interactions between complex campus systems, e.g. energy and water use, transportation and storm water runoff, purchasing and waste, etc.
- How can we learn (in aggregate) about individuals’ waste, energy, transportation, and other behaviors without impinging on privacy?
Janet Vertesi, Sociology Dept, Wallace Hall, Room 122
- Research areas: Sociology of technology; Human-computer interaction; Ubiquitous computing.
- Possible projects: At the intersection of computer science and social science, my students have built mixed reality games, produced artistic and interactive installations, and studied mixed human-robot teams, among other projects.
David Wentzlaff, Engineering Quadrangle, Room 228
Computing, Operating Systems, Sustainable Computing.
- Instrument Princeton's Green (HPCRC) data center
- Investigate power utilization on an processor core implemented in an FPGA
- Dismantle and document all of the components in modern electronics. Invent new ways to build computers that can be recycled easier.
- Other topics in parallel computer architecture or operating systems
Get the Reddit app
ml. Beginners please see learnmachinelearning
What is a good topic for an undergraduate thesis in Machine Learning?
I'm an undergrad Applied Math student who's interested in doing a thesis in Machine Learning. I'm currently taking a Machine Learning class offered at my school, and have some prior experience in the field, although not a ton.
As a beginner, its hard for me to recognize specific areas where I could possibly make some contribution, or do research of some "novel" approach. For example some areas of Machine Learning, such as Collaborative Filtering, have already had large bodies of research done on them, which would make it hard to improve upon the preexisting techniques.
What recommendations do you have for some sources, papers, where I could get some inspiration, or suggest areas/specific problems/specific techniques?
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

Thesis on Machine Learning Methods and Its Applications

2021, IJRASET
In the 1950s, the concept of machine learning was discovered and developed as a subfield of artificial intelligence. However, there were no significant developments or research on it until this decade. Typically, this field of study has developed and expanded since the 1990s. It is a field that will continue to develop in the future due to the difficulty of analysing and processing data as the number of records and documents increases. Due to the increasing data, machine learning focuses on finding the best model for the new data that takes into account all the previous data. Therefore, machine learning research will continue in correlation with this increasing data. This research focuses on the history of machine learning, the methods of machine learning, its applications, and the research that has been conducted on this topic. Our study aims to give researchers a deeper understanding of machine learning, an area of research that is becoming much more popular today, and its applications.
Related Papers
Manisha More
Machine learning is the fastest growing areas of computer science. It has the ability to lets the computer to create the program. It is a subset of Artificial Intelligence (AI), and consists of the more advanced techniques and models that enable computers to figure things out from the data and deliver. It is a field of learning and broadly divided into supervised learning, unsupervised learning, and reinforcement learning. There are many fields where the Machine learning algorithms are used. The objective of the paper is to represent the ML objectives, explore the various ML techniques and algorithms with its applications in the various fields from published papers, workshop materials & material collected from books and material available online on the World Wide Web.
pankaj verma
The field of machine learning is introduced at a conceptual level. The main goal of machine learning is how computers automatically learn without any human invention or assistance so that they can adjust their action accordingly. We are discussing mainly three types of algorithms in machine learning and also discussed ML's features and applications in detail. Supervised ML, In this typeof algorithm, the machine applies what it has learned in its past to new data, in which they use labeled examples, so that they predict future events. Unsupervised ML studies how systems can infer a function, so that they can describe a hidden structure from unlabeled data. Reinforcement ML, is a type of learning method, which interacts with its environment, produces action, as well as discovers errors and rewards.
Journal of Advances in Mathematical & Computational Science. Vol 10, No.3. Pp 1 – 14.
Jerry Sarumi
Machine learning and associated algorithms occupies a pride of place in the execution of automation in the field of computing and its application to addressing contemporary and human-centred problems such as predictions, evaluations, deductions, analytics and analysis. This paper presents types of data and machine learning algorithms in a broader sense. We briefly discuss and explain different machine learning algorithms and real-world application areas based on machine learning. We highlight several research issues and potential future directions
IJESRT Journal
Machine learning [1], a branch of artificial intelligence, that gives computers the ability to learn without being explicitly programmed, means it gives system the ability to learn from data. There are two types of learning techniques: supervised learning and unsupervised learning [2]. This paper summarizes the recent trends of machine learning research.
International Journal for Research in Applied Science & Engineering Technology (IJRASET)
Dr. Manish Kumar Singh
Machine learning has become one of the most envisaged areas of research and development field in modern times. But the area of research related to machine learning is not new. The term machine learning was coined by Arthur Samuel in 1952 and since then lots of developments have been made in this field. The data scientists and the machine learning enthusiasts have developed myriad algorithms from time to time to let the benefit of machine learning reach to each and every field of human endeavors. This paper is an effort to put light on some of the most prominent algorithms that have been used in machine learning field on frequent basis since the time of its inception. Further, we will analyze their area of applications.
International Journal of Advanced Technology and Engineering Exploration
Akash Badone
International Journal of Engineering Applied Sciences and Technology
vishal bari
Today, huge amounts of data are available everywhere. Therefore, analyzing this data is very important to derive useful information from it and develop an algorithm based on this analysis. This can be achieved through data mining and machine learning. Machine learning is an essential part of artificial intelligence used to design algorithms based on data trends and past relationships between data. Machine learning is used in a variety of areas such as bioinformatics, intrusion detection, information retrieval, games, marketing, malware detection, and image decoding. This paper shows the work of various authors in the field of machine learning in various application areas.
Ioannis Vlahavas
IJRASET Publication
This paper describes essential points of machine learning and its application. It seamlessly turns around and teach about the pros and cons of the ML. As well as it covers the real-life application where the machine learning is being used. Different types of machine learning and its algorithms. This paper is giving the detail knowledge about the different algorithms used in machine learning with their applications. There is brief explanation about the Weather Prediction application using the machine learning and also the comparison between various machine learning algorithms used by various researchers for weather prediction.
Sumeet Agarwal
Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
RELATED PAPERS
JMSS, A2Z Journals
Journal of Management and Service Science (JMSS), A 2 Z Journals
Applied Sciences
Grzegorz Dudek
Pooja Ambatkar
Journal of Physics: Conference Series
Jafar Alzubi
IRJET Journal
Kostantinos Demertzis
International Journal of Computer Applications
IJERA Journal
International journal of engineering research and technology
Dr Nitin Rajvanshi
International Journal of Engineering Research and Advanced Technology
rama prasad
International Journal of Scientific Research in Computer Science, Engineering and Information Technology
International Journal of Scientific Research in Computer Science, Engineering and Information Technology IJSRCSEIT
Zachary Barillaro
International Journal of Innovative Technology and Exploring Engineering
atul kathole
Iqbal Muhammad
Artificial Intelligence
mplab.ucsd.edu
Paul Ruvolo
Foundation of Computer Applications
Editor IJATCA , nikhil katoch
International Journal of Scientific Research in Science, Engineering and Technology
International Journal of Scientific Research in Science, Engineering and Technology IJSRSET
RELATED TOPICS
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
Thesis-State
- Research Team
- Feb 23, 2020
Top 60 Thesis/Dissertation Topics in Machine Learning and Artificial Intelligence of 2020
Selecting a focus area and topic for conducting your research and writing thesis/dissertation can be a problematic process-given constant transformation of academic landscape. This is the reason our team has investigated strategies, and come up with the best ones that you can utilize to select the most suited topic for yourself and ensure perfect trajectory to academic success. Our experts collaborated to categorically define six steps that can set you in the right direction. To read more about the process kindly check "Starting Research and Selecting Topic" section in our knowledge base.
We sent out invitation to 134 PhDs on-board with us, to submit the most valuable research topics in CS and IT for the year 2020. Our QA Team received more than thousand topics, which were then thoroughly discussed in expert groups to funnel out a list for our valuable readers. These topics are based mainly on the recent trends in awarded grants and national agendas, as well as potential focus areas that are expected to rise exponentially in next five years. So, please pay close attention to the topics, our team has also defined basic introduction and a strategic overview for each topic in the list, which can be provided to you upon request; kindly feel free to contact us in that regard using the contact provided at the end.
We have divided the list of topics into further focus areas to make the selection easier for you; however, the topics are interdisciplinary and in many ways the focus areas are overlapping. These topics are on high priority by reputable institutes. We strongly recommend to use this list as a source of inspiration. Copying the topics, as it is, is not recommended; although, you can change them to add your own flavor.
In addition, we provide some valuable resources with each focus area that may allow you to dig deeper and shape your understanding of the research topics.
Starting with Machine Learning and AI, a series of posts will be published for the best topics in the following focus areas:
Machine Learning and AI
Computer and Network Security
Big Data and IoT
Information Systems (Cloud and Database Management)
Health IT and Bioinformatics
Visual Computing (AR/VR/CGI)
Software Theory (OS and Architecture)
Neural Generative Models and Representation Learning for Information Retrieval
Controversy Identification Using Machine Learning: Time Dependent Probabilistic Modelling of Controversy Formation based on Social Network Analysis
Automated Product Categorization using Multi-class classification on Data from Amazon
Multi Sensor Fusion for Simultaneous Localization and Mapping on Autonomous Vehicles
Identification of Fake Reviews using Network Analysis and Modeling for E-commerce websites
Approaches for Modeling Data in Multiple Modalities using representation-learning
Predictive, inferential, and mechanistic modeling of cellular-decision making
Reinforcement Learning for enhancing dependability of large distributed control systems: An approach based on advanced simulation structures
Dynamic Scheduling using predictive analytics of Multi Cloud Environments
Rule-based reasoning for knowledge authoring and categorization
Testing deep learning models for Biomedical Imaging: An intelligent image regeneration system
Analysis of the impact of Artificial Intelligence on Distributed Energy Technology using time series analysis
Using deep learning on visual data to predict subjective attributes
An analysis of Hierarchical image classification in CNNs
Using Machine Learning for predicting AQI values based on Satellite Images
Analysis of Landscape images for climate classification: A neural network based approach
Distracted Driver identification: An analysis of most appropriate feature classification and ML algorithms
Predicting Currency exchange rate for recognizing social arbitrage based on News Media
Using Machine Learning models for Credit Card Fraud Detection
Analysis of Economic Networks to Identify Industries: Using Network Characteristics for Node Labeling
Predicting Chaotic systems: An analysis for current Machine Learning Techniques
Using Machine Learning to Model Student Learning in Mobile Apps
Analysis of football match data to predict goals: ANN based approach
Framework for automating feature engineering for deep Q-learning on Markov decision processes: Using NLP for MDP Embeddings
Machine Learning model for risk of Breast Cancer Relapse based on Copy Number
Using DNA Microarray Data for identification of Leukemia Patients: A new classification approach
A comparison study of multinomial classification methods, SVM, Naive Bayes, Logistic Regression and Random Forests, to predict drug-drug interaction severity values from the adverse drug reactions in the FDA’s database
A framework for gradient boosting model predicting CVD risks using multiple EHRs
Social Mdeia Trolls identification using ML: Naive Bayes, Logistic Regression, Kernel SVM, Random Forest, and LSTM neural networks to identify political trolls across social media
A classification framework for Climate Change stance: Using labeled and unlabeled data from Twitter
Collision Avoidance for Urban Air Mobility Vehicles using Markov Decision Processes
Machine Learning on Biochemical Small Datasets: Strategies for Pursuing Predictive Analyses of Human Voltage Gated Sodium Ion Channel (hNaVs) Inhibitors
Optimization model for Antibiotic Treatment using Microculture Results dataset
How accurate is weather data for predicting solar power generation?A new feature engineering approach using National Solar Radiation Database (NSRDB)
Testing Random Network Distillation Theory & Reinforcement Learning for Transfer Learning
Learning With High-Level Attributes: An experiment with fine-grained classification on the Caltech Birds Dataset
Cardiovascular Health prediction using Adaptive Network-Based Fuzzy Inference System (ANFIS)
Biomedical Image Analysis and Reconstruction using Convolutional Neural Networks (CNN)
Using prediction algorithm on acceleration and gyroscopic data of digital pen for character classification: A framework for handwriting identification
Predictive analysis on work visa approval data from the US state department
Transfer Learning to fine-grained visual categorization (FGVC) for Tree Leaf Identification
Labeling Characters as Good or Evil using Sentiment Analysis approach in Cloud Enabled Machine Learning
Prediction of weight-loss based on calorie intake using MYFITNESSPAL DATASET
Price prediction model for the AirBnB offerings based on location
Long-Short Term Memory (LSTM) and Convolutional Neural Network (CNN) models on exchange traded fund close price data to predict future prices.
Machine Learning Model for Tennis Match prediction using prior outcomes and player characteristics
Deep Learning to Collaborative Filtering Model: A novel approach for predictor system
Supervised Learning on Cloud Scale Networks for predicting Link Failure and Localization
An experiment using Deep Neural Networks for tuning of an Aircraft Pitch PID controller
A framework for detecting fake reviews using Yelp Data
SVM classifier and a modified convolutional neural network (CNN) based on Google Inception V3 to diagnose skin images as benign or malignant
Predictive analysis on used car prices
A framework for Yelp Recommendation System using XGboost
A critical review of reinforcement learning algorithms: Defining the way forward
Learning Generative Models using Transformations
New Advances in Sparse Learning, Deep Networks, and Adversarial Learning: Theory and Applications
Prediction system for Diagnosing Schizophrenia: A framework for clinical decision support
Biomedical Entity Recognition
A review into Energy Demand Forecast systems: A novel framework using cloud based AI for real time prediction
Text Classification: A review and way forward
For basic understanding of Machine Learning, take this course for free at Coursera. The course is comprehensive, and one of the best MOOCs till date on any subject.
"Machine Learning" offered by Stanford
In order to get some expert insights into each component of machine learning, alongside some practical approaches, take the " Deep Learning Specialization " offered by Deeplearning.ai .
In order to start with some practical implementation from the get-go, google's offering of " Machine Learning with TensorFlow on GCP " is the best way to go. It will provide you hands-on step-by-step guides on implementing Machine Learning models without any cost or hassle.
On same line as that of the GCP specialization, a much easier and quick way to start is by using Microsoft Azure ML Studio, which provide you with already constructed models and algorithms to play with and implement. Its fun, its easy and its highly valuable: " Implementing Predictive Analytics " and " Predcitive Analytics for IoT ".
⭐⭐⭐⭐⭐ Rating: 4.9 - 23 votes
- Computer Science and IT
- Research Topics
- Learn from Experts
Recent Posts
Best Thesis/Dissertation/Project Topics in Information Systems of 2020
Best RAP/Thesis/Dissertation topics in Applied Accounting of 2020
6 simple steps for finding the best thesis or dissertation topic
Thesis Topics
This list includes topics for potential bachelor or master theses, guided research, projects, seminars, and other activities. Search with Ctrl+F for desired keywords, e.g. ‘machine learning’ or others.
PLEASE NOTE: If you are interested in any of these topics, click the respective supervisor link to send a message with a simple CV, grade sheet, and topic ideas (if any). We will answer shortly.
Of course, your own ideas are always welcome!
Spatial Explicit Machine Learning
Type of work:.
- Guided Research
- Earth Observation
- Machine Learning
- Remote Sensing
- Spatial Awareness Modeling
- Spatial Transferability
Description:
Machine learning models designed and trained to work on a specific regions are not necessarily transferable to other spatially different region. Include a spatially explicit component is mandatory to differentiates behaviors and predictions according to spatial locations. However, it is no clear what is the best way to use this spatial information or which kind of models work best for spatial transferability. In this topic, global remote sensing data will be used for supervised learning in different Earth observation applications.
Feel free to reach out if you have any question or ideas regarding the topic.
Image Super-Resolution in both ways
- auto-encoder
- deep learning
- single image super-resolution
The goal of this project is to develop and evaluate a novel dual-decoder architecture for image super-resolution (SR) [1]. This architecture will utilize a single encoder to extract features from an input image, followed by two decoders: one trained to map the features to a low-resolution (LR) output, and the other to map the features to a high-resolution (HR) output. This approach aims to enhance the SR performance by leveraging the complementary learning objectives of both decoders. The goal of the work is to try different architectures and to analyze different loss formulations as well as the feature space learned by the encoder.
- [1] Hitchhiker’s Guide to Super-Resolution: Introduction and Recent Advances
Applying TaylorShift to Transfomer-based Image Super-Resolution Models
- vision transformer
The aim of this project is to integrate the TaylorShift [1] attention mechanism into the SwinIR model to enhance the efficiency and performance of image super-resolution (SR) [2]. By leveraging the linear complexity of TaylorShift, we intend to improve the processing speed and reduce the memory footprint of SwinIR without compromising its high accuracy in generating high-resolution images from low-resolution inputs. Image super-resolution is a crucial task in computer vision that aims to enhance the resolution of images, making them clearer and more detailed. SwinIR (Swin Transformer for Image Restoration) has shown state-of-the-art performance in various image restoration tasks, including super-resolution. However, the quadratic complexity of its attention mechanism can be a bottleneck, especially for high-resolution images. TaylorShift, a novel reformulation of the Taylor softmax function, addresses this issue by reducing the complexity of the attention mechanism from quadratic to linear. This enables efficient processing of long sequences and high-resolution images while maintaining the ability to capture intricate token-to-token interactions.
- [1] TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax
- [2] Hitchhiker’s Guide to Super-Resolution: Introduction and Recent Advances
Machine Learning-based Surrogate Models for Accelerated Flow Simulations
- Microstructure Property Prediction
- Surrogate Modeling
Surrogate modeling involves creating a simplified and computationally efficient machine learning model that approximates the behavior of a complex system, enabling faster predictions and analysis. For complex systems such as fluids, their behavior is governed by partial differential equations. By solving these PDEs, one can predict how a fluid behaves in a specific environment and conditions. The computational time and resources needed to solve a PDE system depend on the size of the fluid domain and the complexity of the PDE. In practical applications where multiple environments and conditions are to be studied, it becomes very expensive to generate many solutions to such PDEs. Here, modern machine learning or deep learning-based surrogate models which offer fast inference times in the online phase are of interest.
In this work, the focus will be on developing surrogate models to replace the flow simulations in fiber-reinforced composite materials governed by the Navier-Stokes equation. Using a conventional PDE solver, a dataset of reference solutions was generated for supervised learning. In this thesis, your tasks will include the conceptualization and implementation of different ML architectures suited for this task, training and evaluation of the models on the available dataset. You will start with simple fully connected architectures and later extend it to 3D convolutional architectures. Also of interest is the infusion of the available domain knowledge into the ML models, known as physics-informed machine learning.
By applying ML to fluid applications, you will learn to acquire the right amount of domain specific knowledge and analyze your results together with domain experts from the field.
If you are interested, please send me an email with your Curriculum Vitae (CV), your Transcript of records and a short statement about your background in related topics.
References:
- Santos, J.E., Xu, D., Jo, H., Landry, C.J., Prodanović, M., Pyrcz, M.J., 2020. PoreFlow-Net: A 3D convolutional neural network to predict fluid flow through porous media. Advances in Water Resources 138, 103539. https://doi.org/10.1016/j.advwatres.2020.103539
- Kashefi, A., Mukerji, T., 2021. Point-cloud deep learning of porous media for permeability prediction. Physics of Fluids 33, 097109. https://doi.org/10.1063/5.0063904
Sherlock Holmes goes AI - Generative comics art of detective scenes and identikits
- Bias in image generation models
- Deep Learning Frameworks
- Frontend visualization
- Speech-To-Text, Text-to-Image Models
- Transformers, Diffusion Models, Hugging Face
Sherlock Holmes is taking the statement of the witness. The witness is describing the appearance of the perpetrator and the forensic setting they still remember. Your task as the AI investigator will be to generate a comic sketch of the scene and phantom images of the accused person based on the spoken statement of the witness. For this you will use state-of-the-art transformers and visualize the output in an application. As AI investigator you will detect, qualify and quantify bias in the images which are produced by different generation models you have chosen.
This work is embedded in the DFKI KI4Pol lab together with the law enforcement agencies. The stories are fictional you will not work on true crime.
Requirements:
- German level B1/2 or equivalent
- Outstanding academic achievements
- Motivational cover letter
Knowledge Graphs für das Immobilienmanagement
- corporate memory
- knowledge graph
Das Management von Immobilien ist komplex und umfasst verschiedenste Informationsquellen und -objekte zur Durchführung der Prozesse. Ein Corporate Memory kann hier unterstützen in der Analyse und Abbildung des Informationsraums um Wissensdienste zu ermöglichen. Aufgabe ist es, eine Ontologie für das Immobilienmanagement zu entwerfen und beispielhaft ein Szenario zu entwickeln. Für die Materialien und Anwendungspartner sind gute Deutschkenntnisse erforderlich.
Fault and Efficiency Prediction in High Performance Computing
- Master Thesis
- event data modelling
- survival modelling
- time series
High use of resources are thought to be an indirect cause of failures in large cluster systems, but little work has systematically investigated the role of high resource usage on system failures, largely due to the lack of a comprehensive resource monitoring tool which resolves resource use by job and node. This project studies log data of the DFKI Kaiserslautern high performance cluster to consider the predictability of adverse events (node failure, GPU freeze), energy usage and identify the most relevant data within. The second supervisor for this work is Joachim Folz.
Data is available via Prometheus -compatible system:
- Node exporter
- DCGM exporter
- Slurm exporter
- Linking Resource Usage Anomalies with System Failures from Cluster Log Data
- Deep Survival Models
Feel free to reach out if the topic sounds interesting or if you have ideas related to this work. We can then brainstorm a specific research question together. Link to my personal website.
Construction & Application of Enterprise Knowledge Graphs in the E-Invoicing Domain
- Guided Research Project
- knowledge graphs
- knowledge services
- linked data
- semantic web
In recent years knowledge graphs received a lot of attention as well in industry as in science. Knowledge graphs consist of entities and relationships between them and allow integrating new knowledge arbitrarily. Famous instances in industry are knowledge graphs by Microsoft, Google, Facebook or IBM. But beyond these ones, knowledge graphs are also adopted in more domain specific scenarios such as in e-Procurement, e-Invoicing and purchase-to-pay processes. The objective in theses and projects is to explore particular aspects of constructing and/or applying knowledge graphs in the domain of purchase-to-pay processes and e-Invoicing.
Anomaly detection in time-series
- explainability
Working on deep neural networks for making the time-series anomaly detection process more robust. An important aspect of this process is explainability of the decision taken by a network.
Time Series Forecasting Using transformer Networks
- time series forecasting
- transformer networks
Transformer networks have emerged as competent architecture for modeling sequences. This research will primarily focus on using transformer networks for forecasting time series (multivariate/ univariate) and may also involve fusing knowledge into the machine learning architecture.
On This Page
IMAGES
VIDEO
COMMENTS
This article provides a list of 20 potential thesis ideas for an undergraduate program in machine learning and deep learning in 2023. Each thesis idea includes an introduction, which presents a brief overview of the topic and the research objectives. The ideas provided are related to different areas of machine learning and deep learning, such ...
A comprehensive list of research topics ideas in the AI and machine learning area. Includes access to a free webinar and topic evaluator. About Us; Services. 1-On-1 Coaching. Topic Ideation; ... If you're just starting out exploring AI-related research topics for your dissertation, thesis or research project, you've come to the right place.
Potential thesis topics in this area: a) Compare inference speed with sum-product networks and Bayesian networks. Characterize situations when one model is better than the other. ... and machine learning could now offer a substantial contribution. Security capture-the-flag simulations are particularly well-suited as a testbed for the ...
In this tech-driven world, selecting research and thesis topics in machine learning projects is the first choice of masters and Doctorate scholars. Selecting and working on a thesis topic in machine learning is not an easy task as machine learning uses statistical algorithms to make computers work in a certain way without being explicitly ...
PhD Dissertations [All are .pdf files] Probabilistic Reinforcement Learning: Using Data to Define Desired Outcomes, and Inferring How to Get There Benjamin Eysenbach, 2023. Data-driven Decisions - An Anomaly Detection Perspective Shubhranshu Shekhar, 2023. METHODS AND APPLICATIONS OF EXPLAINABLE MACHINE LEARNING Joon Sik Kim, 2023. Applied Mathematics of the Future Kin G. Olivares, 2023
Dr. Ola PETERSSON. HT2015 Computer Science 15HT - 5DV50E/4DV50E. Master Thesis Using Machine Learning Methods for Evaluating the Quality of Technical Documents. Abstract In the context of an increasingly networked world, the availability of high quality transla- tions is critical for success in the context of the growing international competition.
of the basics of machine learning, it might be better understood as a collection of tools that can be applied to a speci c subset of problems. 1.2 What Will This Book Teach Me? The purpose of this book is to provide you the reader with the following: a framework with which to approach problems that machine learning learning might help solve ...
Machine learning (ML) systems are remarkably successful on a variety of benchmarks across sev- ... This thesis focuses on an extreme version of this brittleness, adversarial examples, where ... Progress on this widely-studied topic has been limited by the following critical roadblocks which we address in this thesis. Challenge 1: Worst-case ...
This machine learning dissertation comprises four chapters. The first is an introduction to the topics of the dissertation and the remaining chapters contain the main results. Chapter 2 gives new results for consistency of maximum likelihood estimators with a focus on multivariate mixed models.
This dissertation explores three topics related to random forests: tree aggregation, variable importance, and robustness. 10. Climate Data Computing: Optimal Interpolation, Averaging, Visualization and Delivery. This dissertation solves two important problems in the modern analysis of big climate data.
Machine learning research is at the heart of the AI revolution. It underpins the development of intelligent systems capable of making predictions, automating tasks, and improving decision-making across industries. The importance of this research can be summarized as follows: Advancements in Technology.
Let us now have an idea about various headings to be included in any thesis topics for machine learning. Introduction - overview of the thesis; Related / Existing works - presents of existing research; Problems definition/statements - identify and highlight the problems; Research methodology - convey the proposed concepts; Results and Discussion - discuss the results of the proposed ...
Advancements in machine learning techniques have encouraged scholars to focus on convolutional neural network (CNN) based solutions for object detection and pose estimation tasks. Most … Year: 2020 Contributor: Derman, Can Eren (creator) Bahar, Iris (thesis advisor) Taubin, Gabriel (reader) Brown University. School of Engineering (sponsor ...
2. Intelligent Internet Ads Generation (Classification) This is one of the most interesting topics for me. The reason is because the revenue generated or expended by ads campaign depends not just on the volume of the ads, but also on the relevance of the ads. Therefore it is possible to increase revenue and reduce spending by developing a ...
Supervised Machine Learning. It is a good topic for machine learning masters thesis. It is a type of machine learning algorithm in which makes predictions based on known data-sets. Input and output is provided to the system along with feedback. Supervised Learning is further classified into classification and regression problems.
Open Topics We offer multiple Bachelor/Master theses, Guided Research projects and IDPs in the area of data mining/machine learning. A non-exhaustive list of open topics is listed below.. If you are interested in a thesis or a guided research project, please send your CV and transcript of records to Prof. Stephan Günnemann via email and we will arrange a meeting to talk about the potential ...
Below you can see the thesis topics for 2022-2023. We offer 3 different thesis formats: - Format 1 : Regular thesis (fully supervised by KU Leuven) - Format 2 : Thesis in cooperation with a company (supervised by KU Leuven and the company) - Format 3 : Thesis with a company project within a company (supervised by the company) NOTE: Additional ...
Any interesting project related to AI, machine learning, and data analysis. Lydia Liu, Room 414. Available for single-semester IW and senior thesis advising, 2024-2025. Research Areas: algorithmic decision making, machine learning and society; Selected topics:
The first thing I want to stress is that you should take the master thesis topic seriously for the following reasons: it has the highest credits amount in the master's degree program, which is 15 credits. Meaning that it is a big commitment of your time and efforts. Normally a course is about 5 credits, so the master thesis requires a ...
For example, perhaps take a walk through a park, take pictures of all of the plants of one species, and see if you can use machine learning that can figure out things like degree of branching, age, pest prevalence, etc., from images of the plant. Undergrad ML TA. I suggest you find a researcher at your university, preferably in biology ...
This research focuses on the history of machine learning, the methods of machine learning, its applications, and the research that has been conducted on this topic. Our study aims to give researchers a deeper understanding of machine learning, an area of research that is becoming much more popular today, and its applications. See Full PDF.
Machine Learning and AI. Topics: Neural Generative Models and Representation Learning for Information Retrieval. Controversy Identification Using Machine Learning: Time Dependent Probabilistic Modelling of Controversy Formation based on Social Network Analysis. Automated Product Categorization using Multi-class classification on Data from Amazon.
Thesis Topics. This list includes topics for potential bachelor or master theses, guided research, projects, seminars, and other activities. Search with Ctrl+F for desired keywords, e.g. 'machine learning' or others. PLEASE NOTE: If you are interested in any of these topics, click the respective supervisor link to send a message with a ...